RMLVQA: A Margin Loss Approach for Visual Question Answering With Language Biases
{kind=link}
Abstract
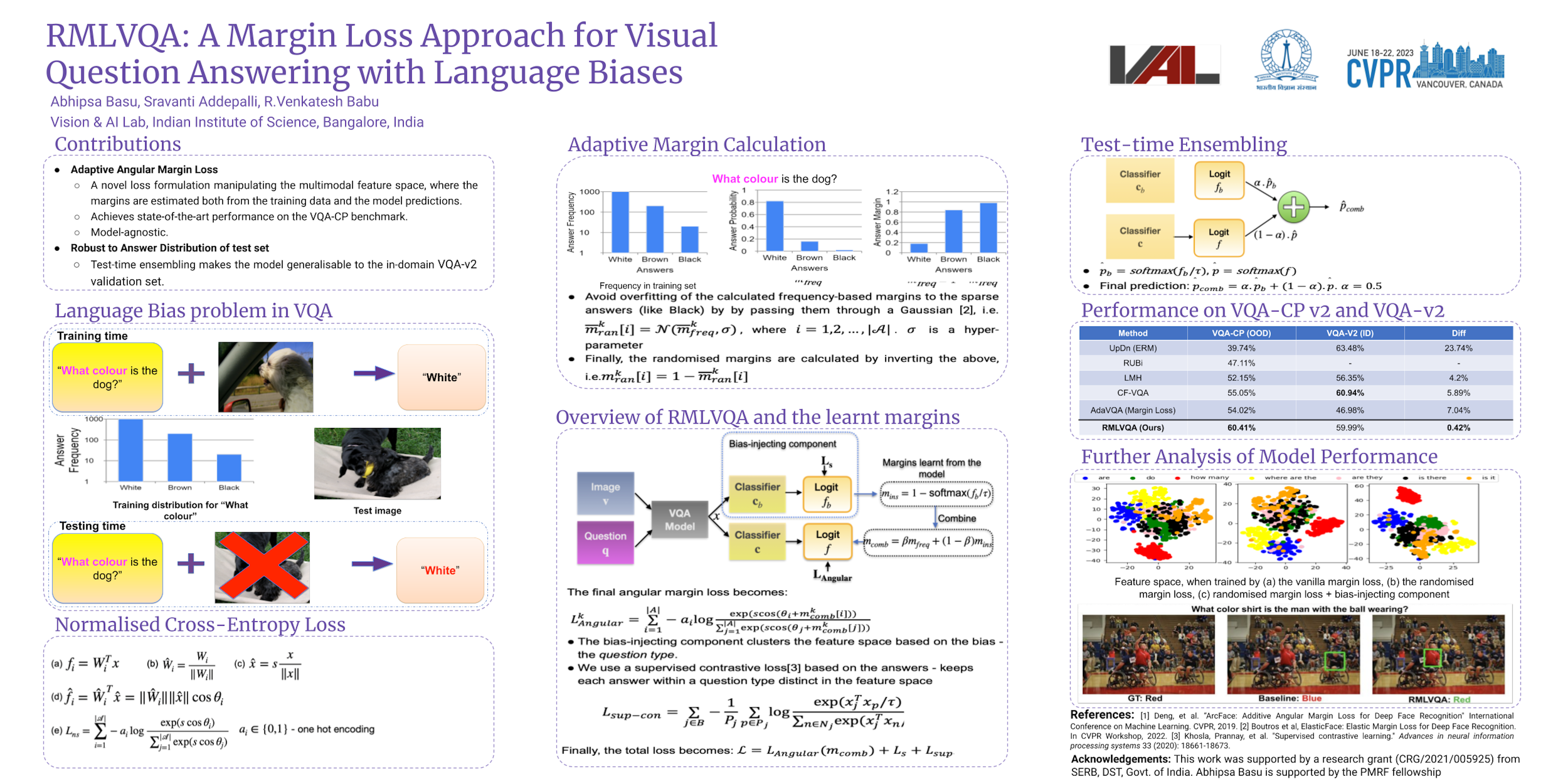
Visual Question Answering models have been shown to suffer from language biases, where the model learns a correlation between the question and the answer, ignoring the image. While early works attempted to use question-only models or data augmentations to reduce this bias, we propose an adaptive margin loss approach having two components. The first component considers the frequency of answers within a question type in the training data, which addresses the concern of the class-imbalance causing the language biases. However, it does not take into account the answering difficulty of the samples, which impacts their learning. We address this through the second component, where instance-specific margins are learnt, allowing the model to distinguish between samples of varying complexity. We introduce a bias-injecting component to our model, and compute the instance-specific margins from the confidence of this component. We combine these with the estimated margins to consider both answer-frequency and task-complexity in the training loss. We show that, while the margin loss is effective for out-of-distribution (ood) data, the bias-injecting component is essential for generalising to in-distribution (id) data. Our proposed approach, Robust Margin Loss for Visual Question Answering (RMLVQA) improves upon the existing state-of-the-art results when compared to augmentation-free methods on benchmark VQA datasets suffering from language biases, while maintaining competitive performance on id data, making our method the most robust one among all comparable methods.