MP-Former: Mask-Piloted Transformer for Image Segmentation
{kind=link}
Abstract
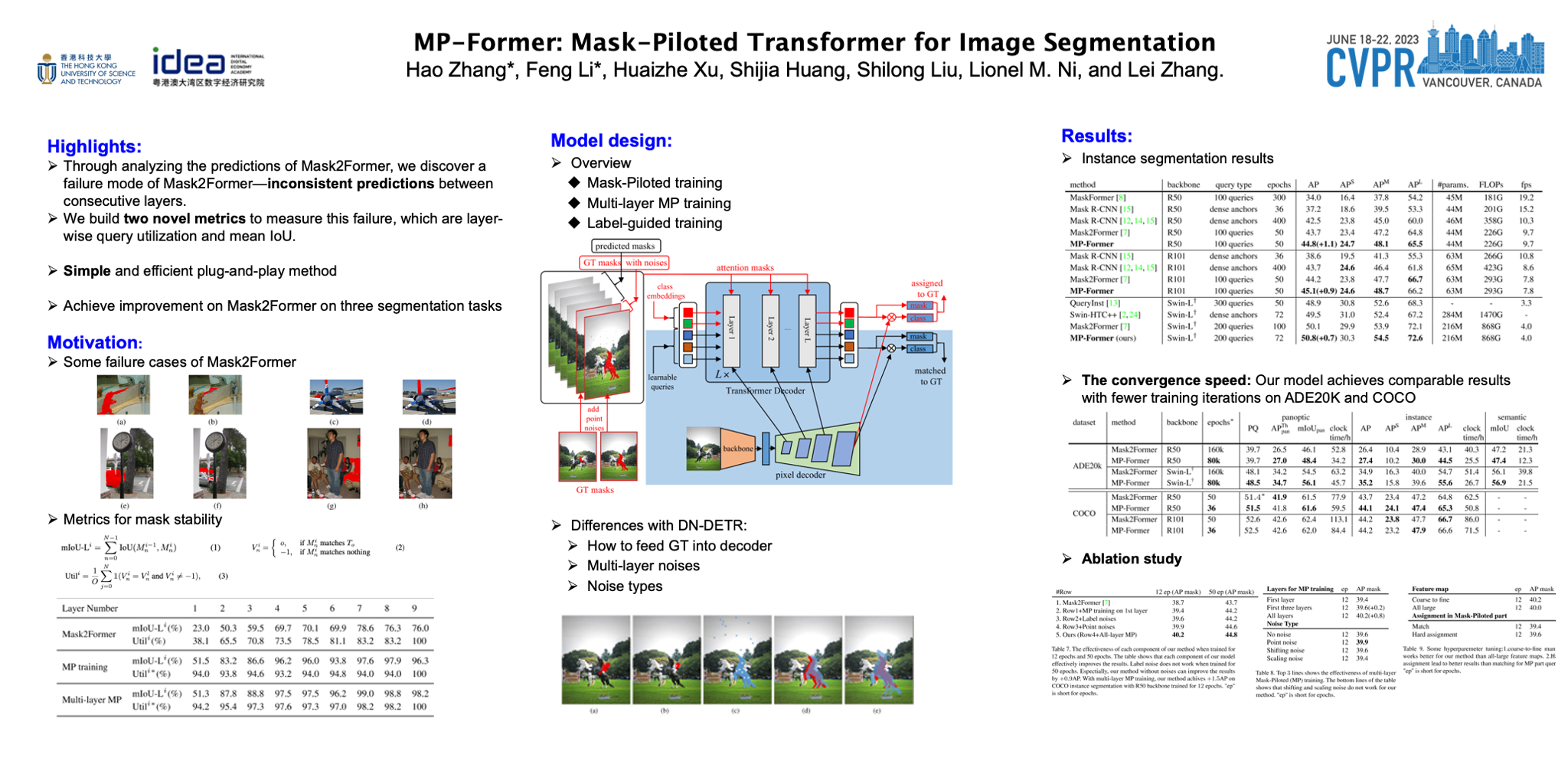
We present a mask-piloted Transformer which improves masked-attention in Mask2Former for image segmentation. The improvement is based on our observation that Mask2Former suffers from inconsistent mask predictions between consecutive decoder layers, which leads to inconsistent optimization goals and low utilization of decoder queries. To address this problem, we propose a mask-piloted training approach, which additionally feeds noised ground-truth masks in masked-attention and trains the model to reconstruct the original ones. Compared with the predicted masks used in mask-attention, the ground-truth masks serve as a pilot and effectively alleviate the negative impact of inaccurate mask predictions in Mask2Former. Based on this technique, our MP-Former achieves a remarkable performance improvement on all three image segmentation tasks (instance, panoptic, and semantic), yielding +2.3 AP and +1.6 mIoU on the Cityscapes instance and semantic segmentation tasks with a ResNet-50 backbone. Our method also significantly speeds up the training, outperforming Mask2Former with half of the number of training epochs on ADE20K with both a ResNet-50 and a Swin-L backbones. Moreover, our method only introduces little computation during training and no extra computation during inference. Our code will be released at https://github.com/IDEA-Research/MP-Former.