Towards End-to-End Generative Modeling of Long Videos With Memory-Efficient Bidirectional Transformers
{kind=link}
Abstract
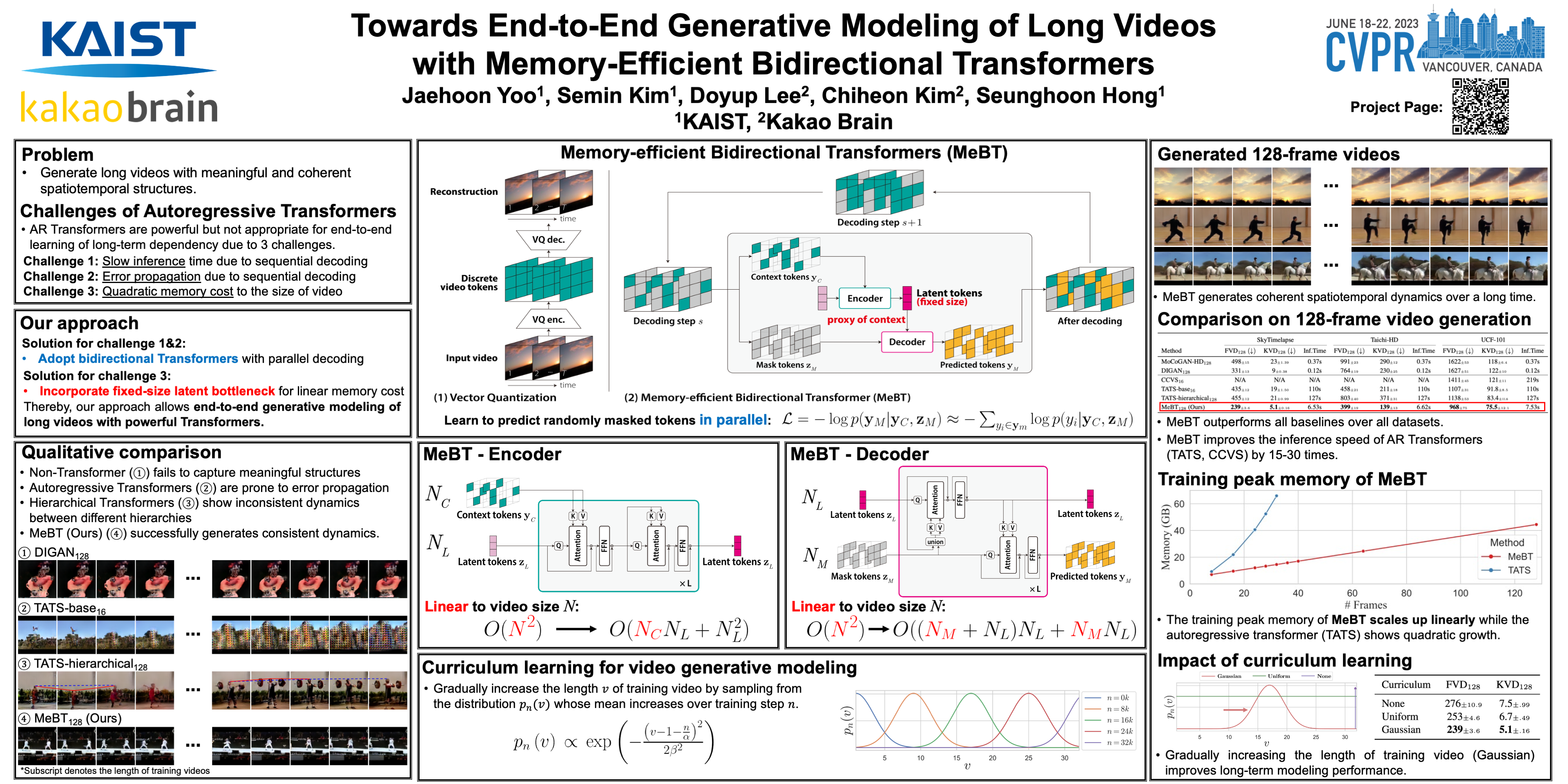
Autoregressive transformers have shown remarkable success in video generation. However, the transformers are prohibited from directly learning the long-term dependency in videos due to the quadratic complexity of self-attention, and inherently suffering from slow inference time and error propagation due to the autoregressive process. In this paper, we propose Memory-efficient Bidirectional Transformer (MeBT) for end-to-end learning of long-term dependency in videos and fast inference. Based on recent advances in bidirectional transformers, our method learns to decode the entire spatio-temporal volume of a video in parallel from partially observed patches. The proposed transformer achieves a linear time complexity in both encoding and decoding, by projecting observable context tokens into a fixed number of latent tokens and conditioning them to decode the masked tokens through the cross-attention. Empowered by linear complexity and bidirectional modeling, our method demonstrates significant improvement over the autoregressive Transformers for generating moderately long videos in both quality and speed.