ScaleKD: Distilling Scale-Aware Knowledge in Small Object Detector
{kind=link}
Abstract
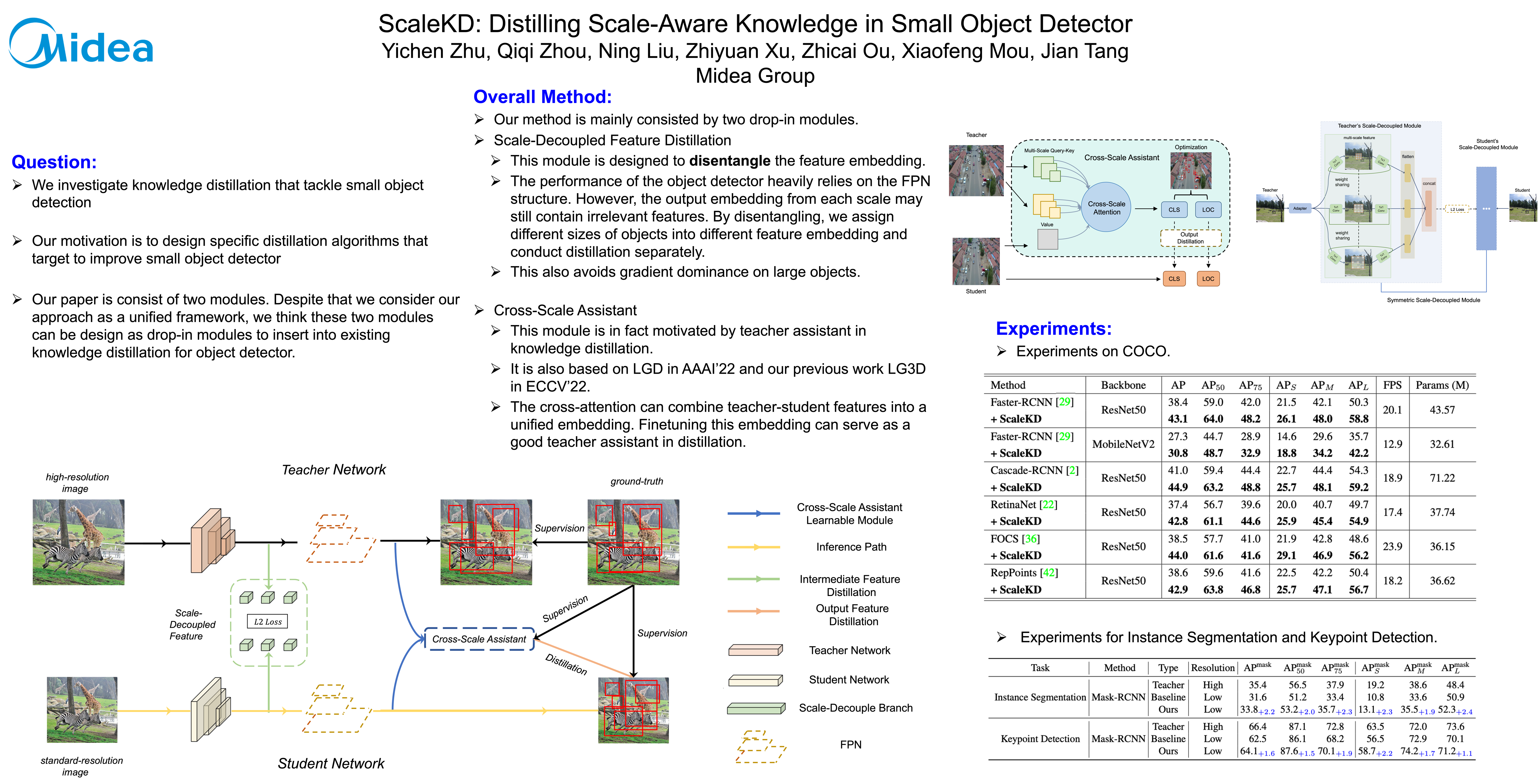
Despite the prominent success of general object detection, the performance and efficiency of Small Object Detection (SOD) are still unsatisfactory. Unlike existing works that struggle to balance the trade-off between inference speed and SOD performance, in this paper, we propose a novel Scale-aware Knowledge Distillation (ScaleKD), which transfers knowledge of a complex teacher model to a compact student model. We design two novel modules to boost the quality of knowledge transfer in distillation for SOD: 1) a scale-decoupled feature distillation module that disentangled teacher’s feature representation into multi-scale embedding that enables explicit feature mimicking of the student model on small objects. 2) a cross-scale assistant to refine the noisy and uninformative bounding boxes prediction student models, which can mislead the student model and impair the efficacy of knowledge distillation. A multi-scale cross-attention layer is established to capture the multi-scale semantic information to improve the student model. We conduct experiments on COCO and VisDrone datasets with diverse types of models, i.e., two-stage and one-stage detectors, to evaluate our proposed method. Our ScaleKD achieves superior performance on general detection performance and obtains spectacular improvement regarding the SOD performance.