Frame Flexible Network
{kind=link}
Abstract
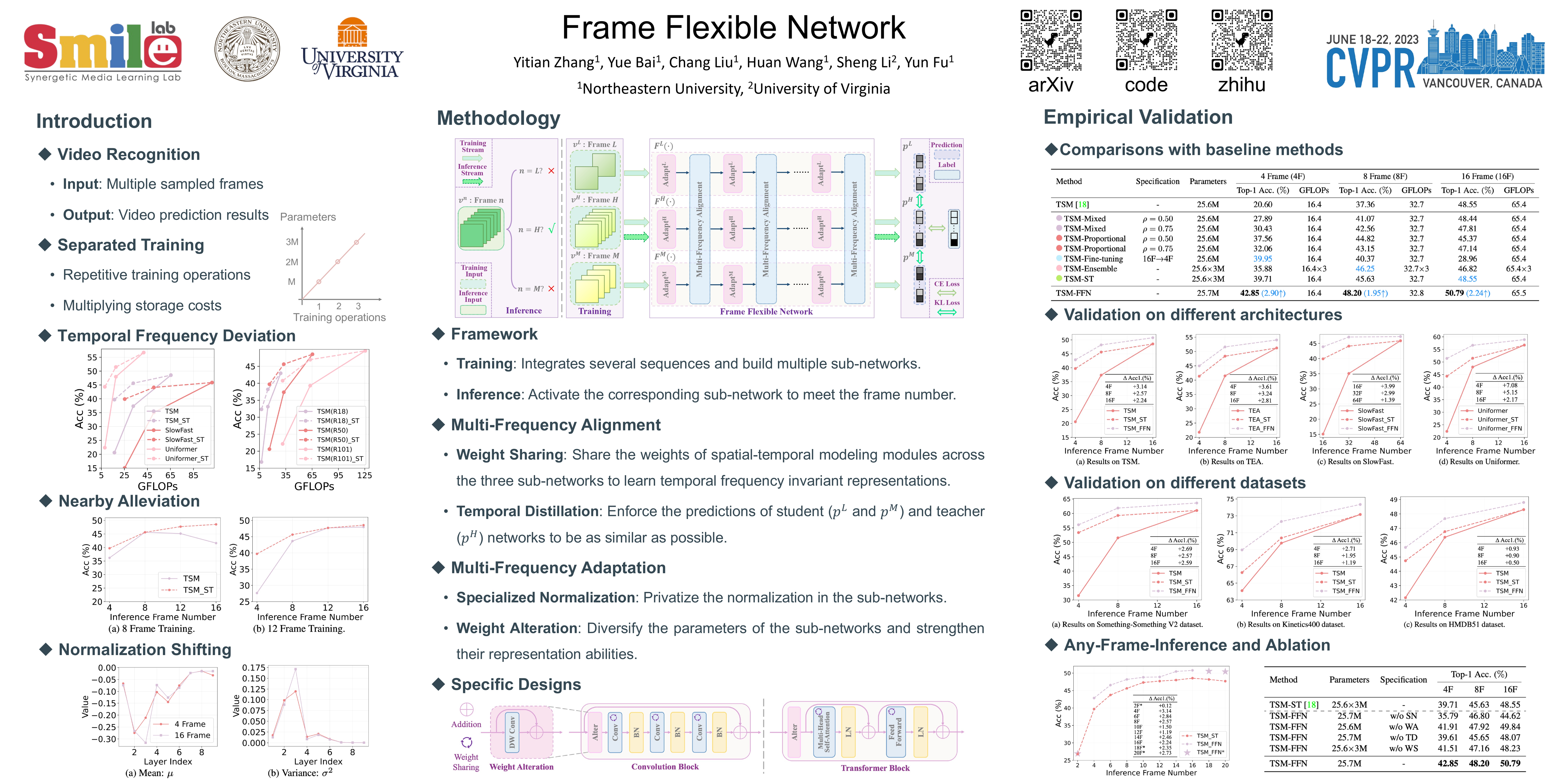
Existing video recognition algorithms always conduct different training pipelines for inputs with different frame numbers, which requires repetitive training operations and multiplying storage costs. If we evaluate the model using other frames which are not used in training, we observe the performance will drop significantly (see Fig.1, which is summarized as Temporal Frequency Deviation phenomenon. To fix this issue, we propose a general framework, named Frame Flexible Network (FFN), which not only enables the model to be evaluated at different frames to adjust its computation, but also reduces the memory costs of storing multiple models significantly. Concretely, FFN integrates several sets of training sequences, involves Multi-Frequency Alignment (MFAL) to learn temporal frequency invariant representations, and leverages Multi-Frequency Adaptation (MFAD) to further strengthen the representation abilities. Comprehensive empirical validations using various architectures and popular benchmarks solidly demonstrate the effectiveness and generalization of FFN (e.g., 7.08/5.15/2.17% performance gain at Frame 4/8/16 on Something-Something V1 dataset over Uniformer). Code is available at https://github.com/BeSpontaneous/FFN.