Achieving a Better Stability-Plasticity Trade-Off via Auxiliary Networks in Continual Learning
{kind=link}
Abstract
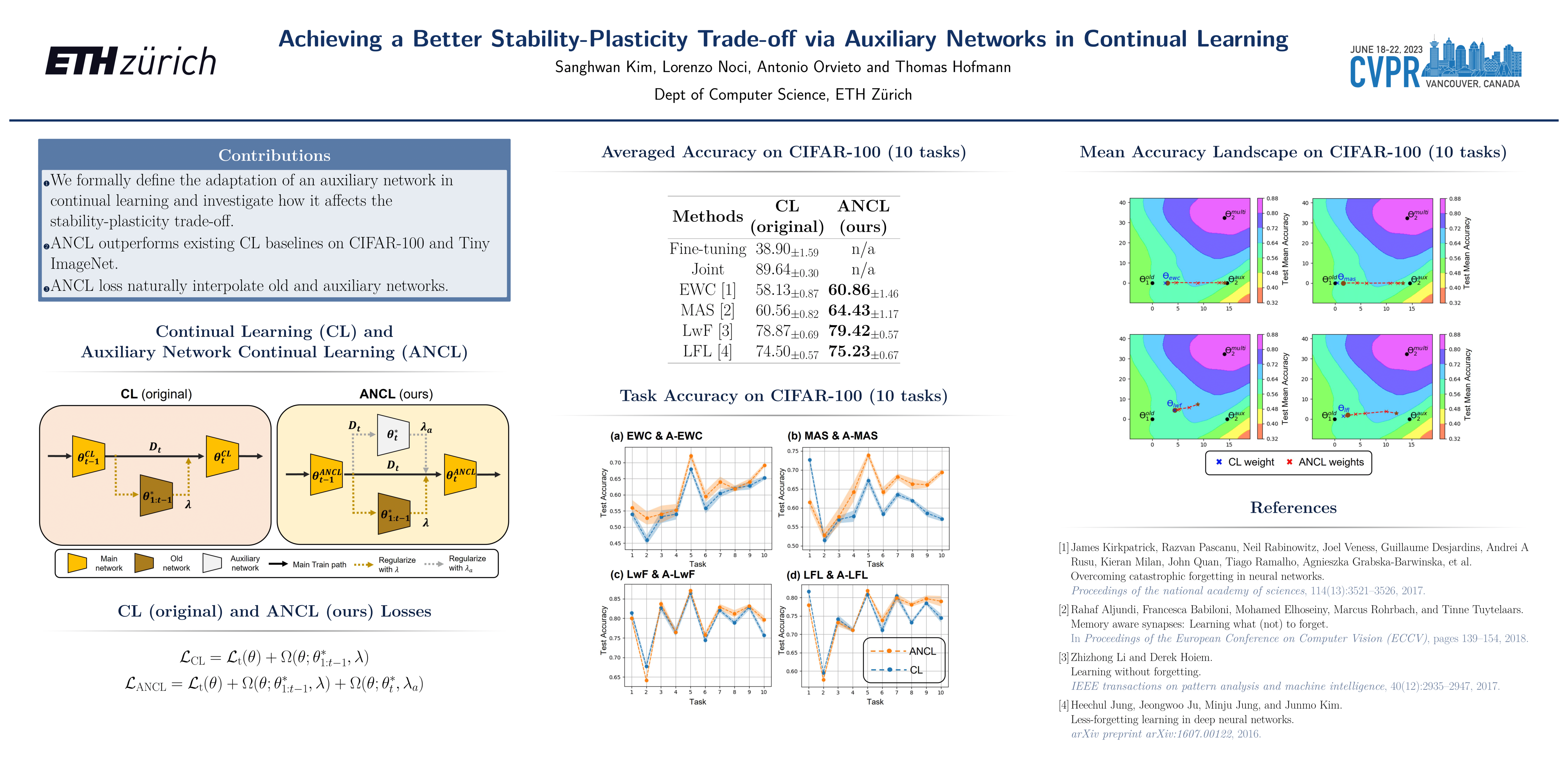
In contrast to the natural capabilities of humans to learn new tasks in a sequential fashion, neural networks are known to suffer from catastrophic forgetting, where the model’s performances on old tasks drop dramatically after being optimized for a new task. Since then, the continual learning (CL) community has proposed several solutions aiming to equip the neural network with the ability to learn the current task (plasticity) while still achieving high accuracy on the previous tasks (stability). Despite remarkable improvements, the plasticity-stability trade-off is still far from being solved, and its underlying mechanism is poorly understood. In this work, we propose Auxiliary Network Continual Learning (ANCL), a novel method that applies an additional auxiliary network which promotes plasticity to the continually learned model which mainly focuses on stability. More concretely, the proposed framework materializes in a regularizer that naturally interpolates between plasticity and stability, surpassing strong baselines on task incremental and class incremental scenarios. Through extensive analyses on ANCL solutions, we identify some essential principles beneath the stability-plasticity trade-off.