Learning Audio-Visual Source Localization via False Negative Aware Contrastive Learning
{kind=link}
Abstract
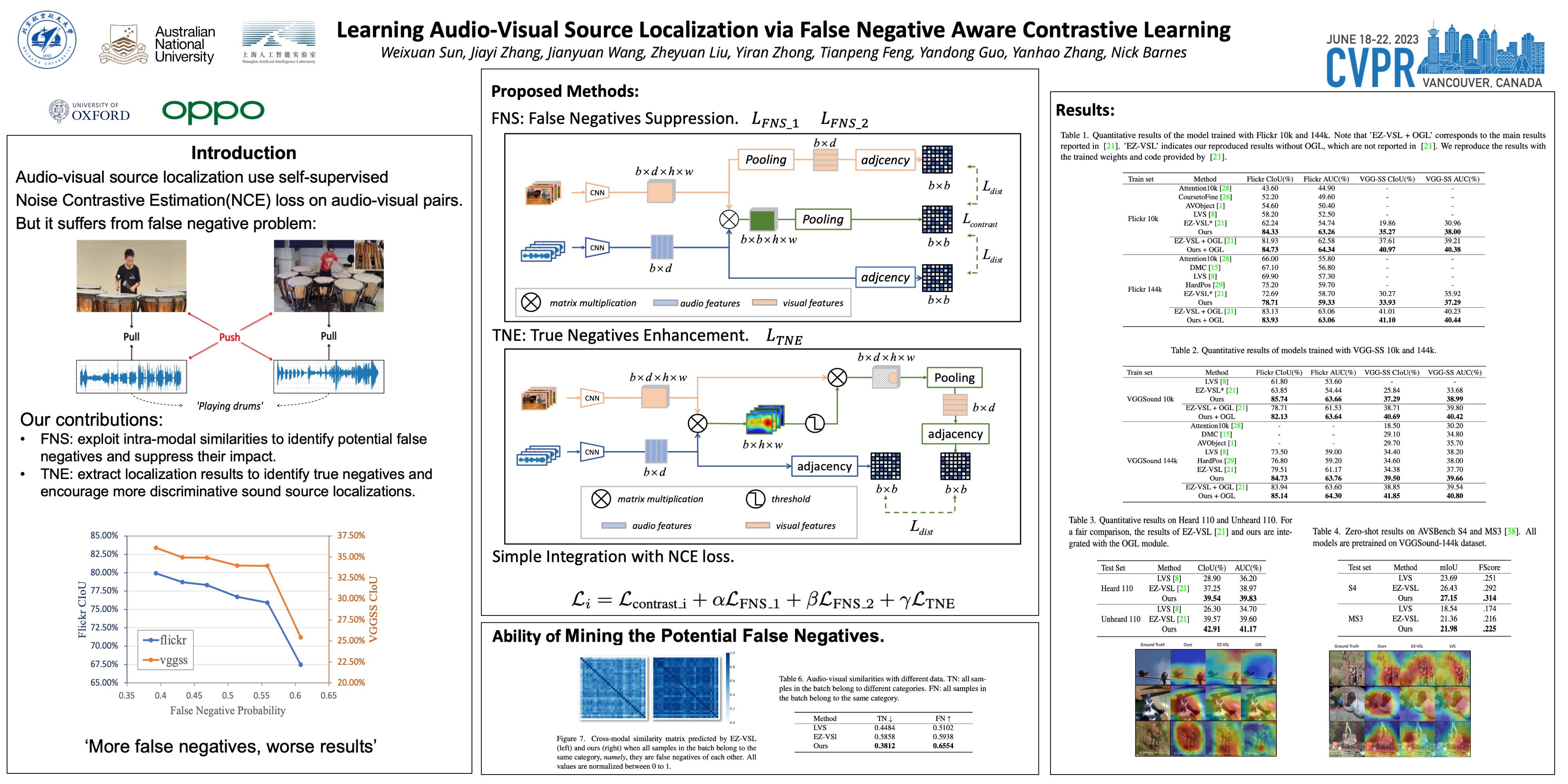
Self-supervised audio-visual source localization aims to locate sound-source objects in video frames without extra annotations. Recent methods often approach this goal with the help of contrastive learning, which assumes only the audio and visual contents from the same video are positive samples for each other. However, this assumption would suffer from false negative samples in real-world training. For example, for an audio sample, treating the frames from the same audio class as negative samples may mislead the model and therefore harm the learned representations (e.g., the audio of a siren wailing may reasonably correspond to the ambulances in multiple images). Based on this observation, we propose a new learning strategy named False Negative Aware Contrastive (FNAC) to mitigate the problem of misleading the training with such false negative samples. Specifically, we utilize the intra-modal similarities to identify potentially similar samples and construct corresponding adjacency matrices to guide contrastive learning. Further, we propose to strengthen the role of true negative samples by explicitly leveraging the visual features of sound sources to facilitate the differentiation of authentic sounding source regions. FNAC achieves state-of-the-art performances on Flickr-SoundNet, VGG-Sound, and AVSBench, which demonstrates the effectiveness of our method in mitigating the false negative issue. The code is available at https://github.com/OpenNLPLab/FNAC_AVL