Rebalancing Batch Normalization for Exemplar-Based Class-Incremental Learning
{kind=link}
Abstract
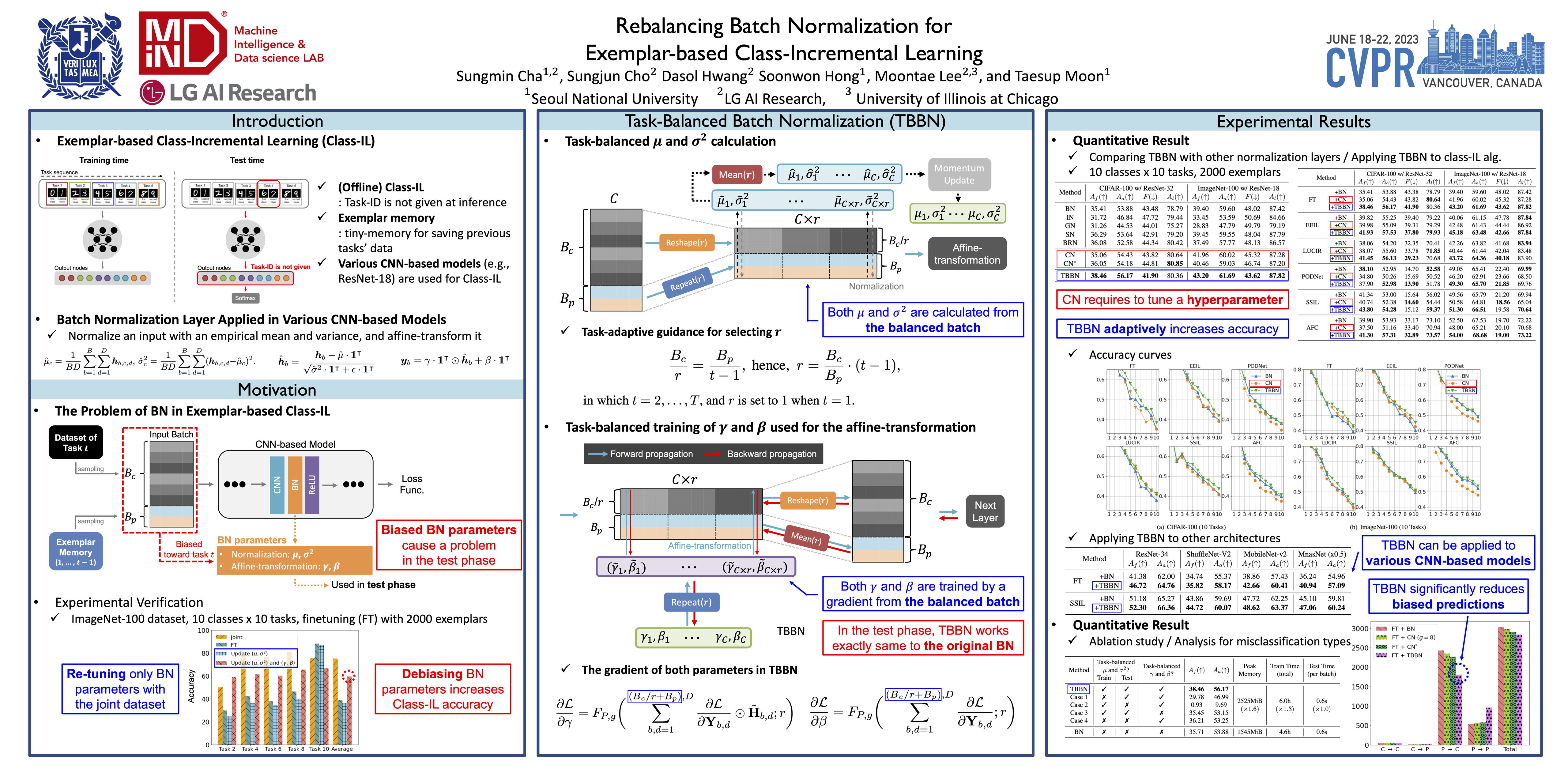
Batch Normalization (BN) and its variants has been extensively studied for neural nets in various computer vision tasks, but relatively little work has been dedicated to studying the effect of BN in continual learning. To that end, we develop a new update patch for BN, particularly tailored for the exemplar-based class-incremental learning (CIL). The main issue of BN in CIL is the imbalance of training data between current and past tasks in a mini-batch, which makes the empirical mean and variance as well as the learnable affine transformation parameters of BN heavily biased toward the current task --- contributing to the forgetting of past tasks. While one of the recent BN variants has been developed for “online” CIL, in which the training is done with a single epoch, we show that their method does not necessarily bring gains for “offline” CIL, in which a model is trained with multiple epochs on the imbalanced training data. The main reason for the ineffectiveness of their method lies in not fully addressing the data imbalance issue, especially in computing the gradients for learning the affine transformation parameters of BN. Accordingly, our new hyperparameter-free variant, dubbed as Task-Balanced BN (TBBN), is proposed to more correctly resolve the imbalance issue by making a horizontally-concatenated task-balanced batch using both reshape and repeat operations during training. Based on our experiments on class incremental learning of CIFAR-100, ImageNet-100, and five dissimilar task datasets, we demonstrate that our TBBN, which works exactly the same as the vanilla BN in the inference time, is easily applicable to most existing exemplar-based offline CIL algorithms and consistently outperforms other BN variants.