Learning To Zoom and Unzoom
{kind=link}
Abstract
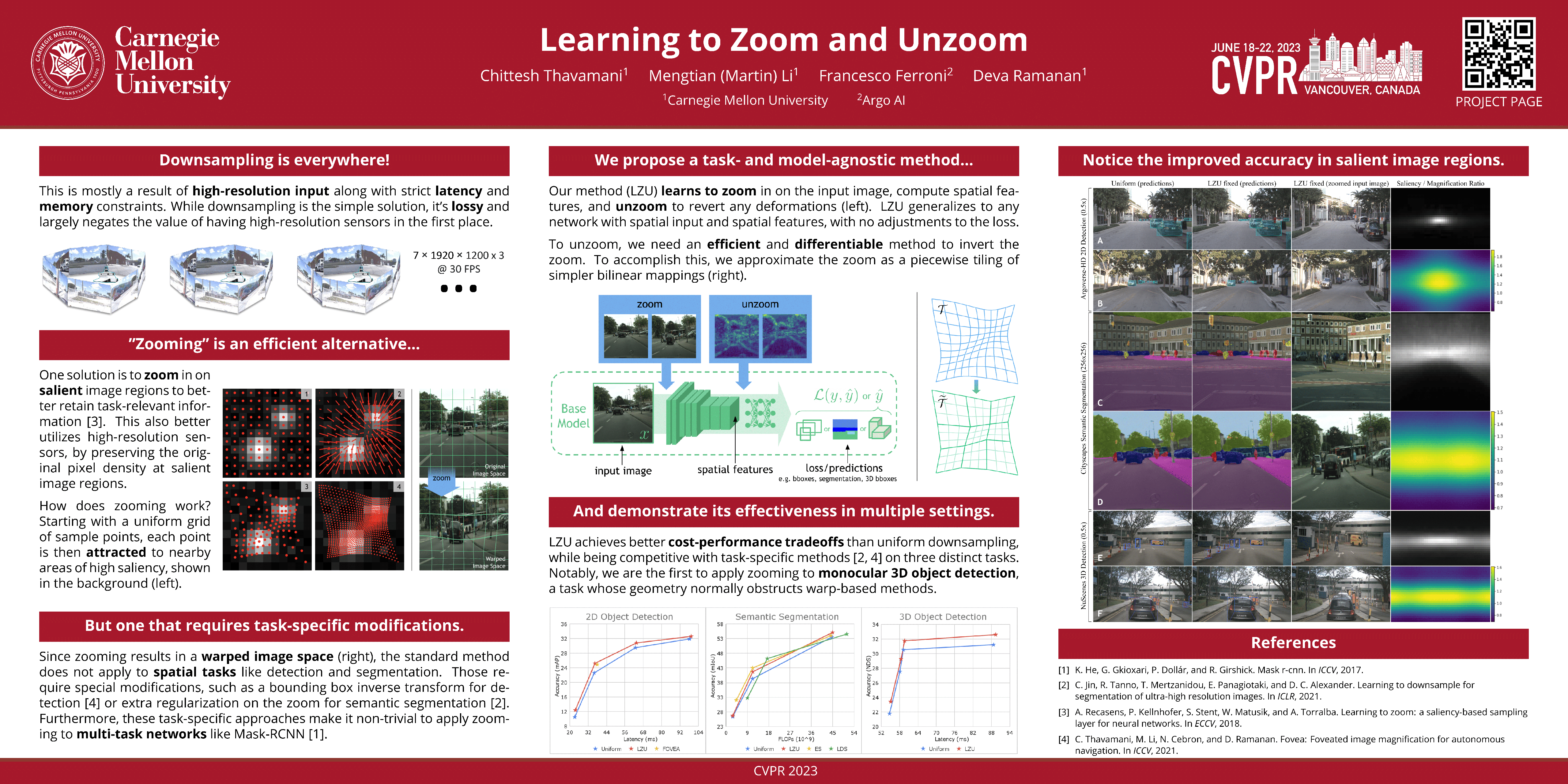
Many perception systems in mobile computing, autonomous navigation, and AR/VR face strict compute constraints that are particularly challenging for high-resolution input images. Previous works propose nonuniform downsamplers that “learn to zoom” on salient image regions, reducing compute while retaining task-relevant image information. However, for tasks with spatial labels (such as 2D/3D object detection and semantic segmentation), such distortions may harm performance. In this work (LZU), we “learn to zoom” in on the input image, compute spatial features, and then “unzoom” to revert any deformations. To enable efficient and differentiable unzooming, we approximate the zooming warp with a piecewise bilinear mapping that is invertible. LZU can be applied to any task with 2D spatial input and any model with 2D spatial features, and we demonstrate this versatility by evaluating on a variety of tasks and datasets: object detection on Argoverse-HD, semantic segmentation on Cityscapes, and monocular 3D object detection on nuScenes. Interestingly, we observe boosts in performance even when high-resolution sensor data is unavailable, implying that LZU can be used to “learn to upsample” as well. Code and additional visuals are available at https://tchittesh.github.io/lzu/.