Uncurated Image-Text Datasets: Shedding Light on Demographic Bias
 Highlight
Highlight
{kind=link}
Abstract
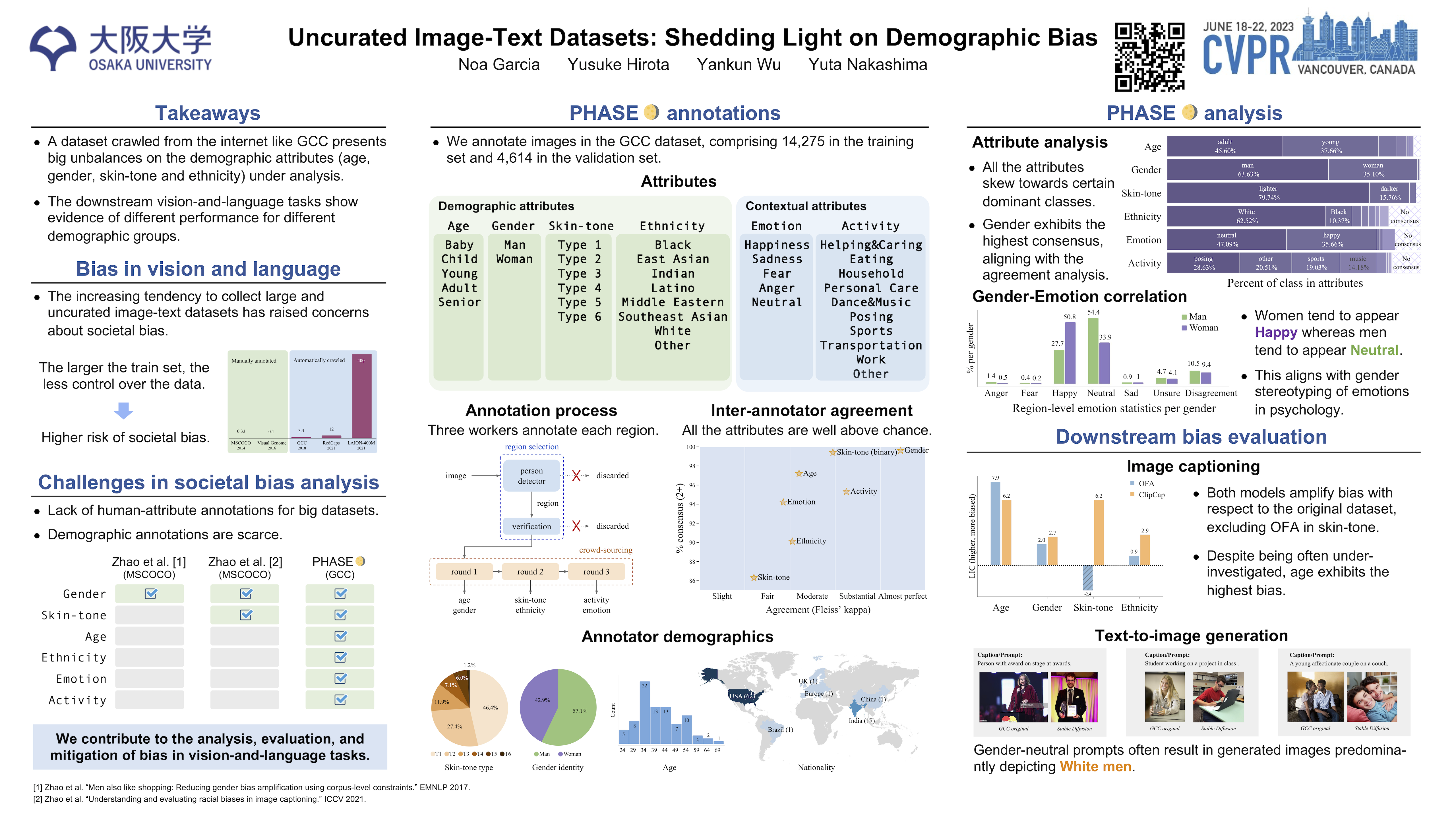
The increasing tendency to collect large and uncurated datasets to train vision-and-language models has raised concerns about fair representations. It is known that even small but manually annotated datasets, such as MSCOCO, are affected by societal bias. This problem, far from being solved, may be getting worse with data crawled from the Internet without much control. In addition, the lack of tools to analyze societal bias in big collections of images makes addressing the problem extremely challenging. Our first contribution is to annotate part of the Google Conceptual Captions dataset, widely used for training vision-and-language models, with four demographic and two contextual attributes. Our second contribution is to conduct a comprehensive analysis of the annotations, focusing on how different demographic groups are represented. Our last contribution lies in evaluating three prevailing vision-and-language tasks: image captioning, text-image CLIP embeddings, and text-to-image generation, showing that societal bias is a persistent problem in all of them.