Towards a Smaller Student: Capacity Dynamic Distillation for Efficient Image Retrieval
{kind=link}
Abstract
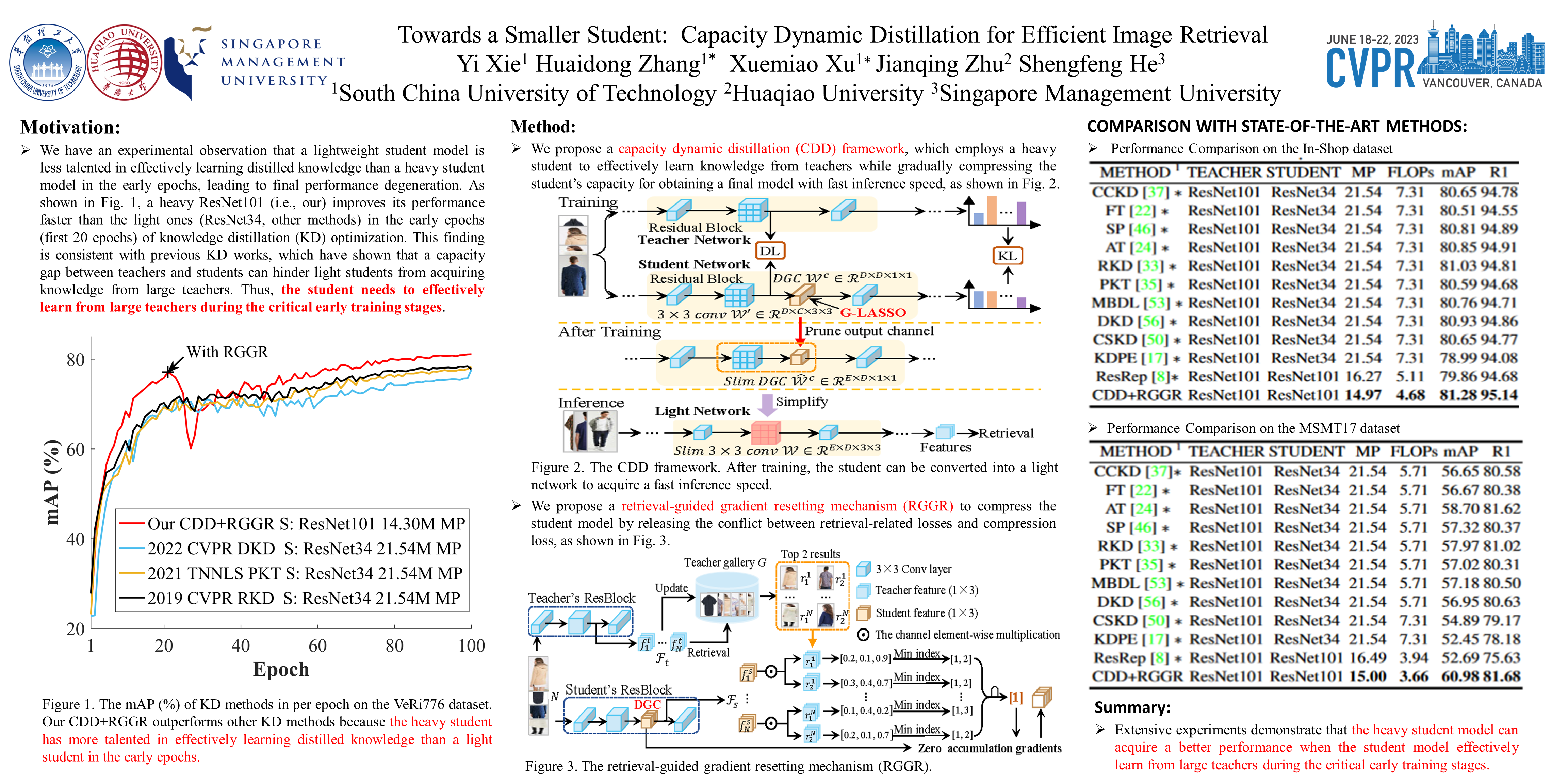
Previous Knowledge Distillation based efficient image retrieval methods employ a lightweight network as the student model for fast inference. However, the lightweight student model lacks adequate representation capacity for effective knowledge imitation during the most critical early training period, causing final performance degeneration. To tackle this issue, we propose a Capacity Dynamic Distillation framework, which constructs a student model with editable representation capacity. Specifically, the employed student model is initially a heavy model to fruitfully learn distilled knowledge in the early training epochs, and the student model is gradually compressed during the training. To dynamically adjust the model capacity, our dynamic framework inserts a learnable convolutional layer within each residual block in the student model as the channel importance indicator. The indicator is optimized simultaneously by the image retrieval loss and the compression loss, and a retrieval-guided gradient resetting mechanism is proposed to release the gradient conflict. Extensive experiments show that our method has superior inference speed and accuracy, e.g., on the VeRi-776 dataset, given the ResNet101 as a teacher, our method saves 67.13% model parameters and 65.67% FLOPs without sacrificing accuracy.