A Generalized Framework for Video Instance Segmentation
{kind=link}
Abstract
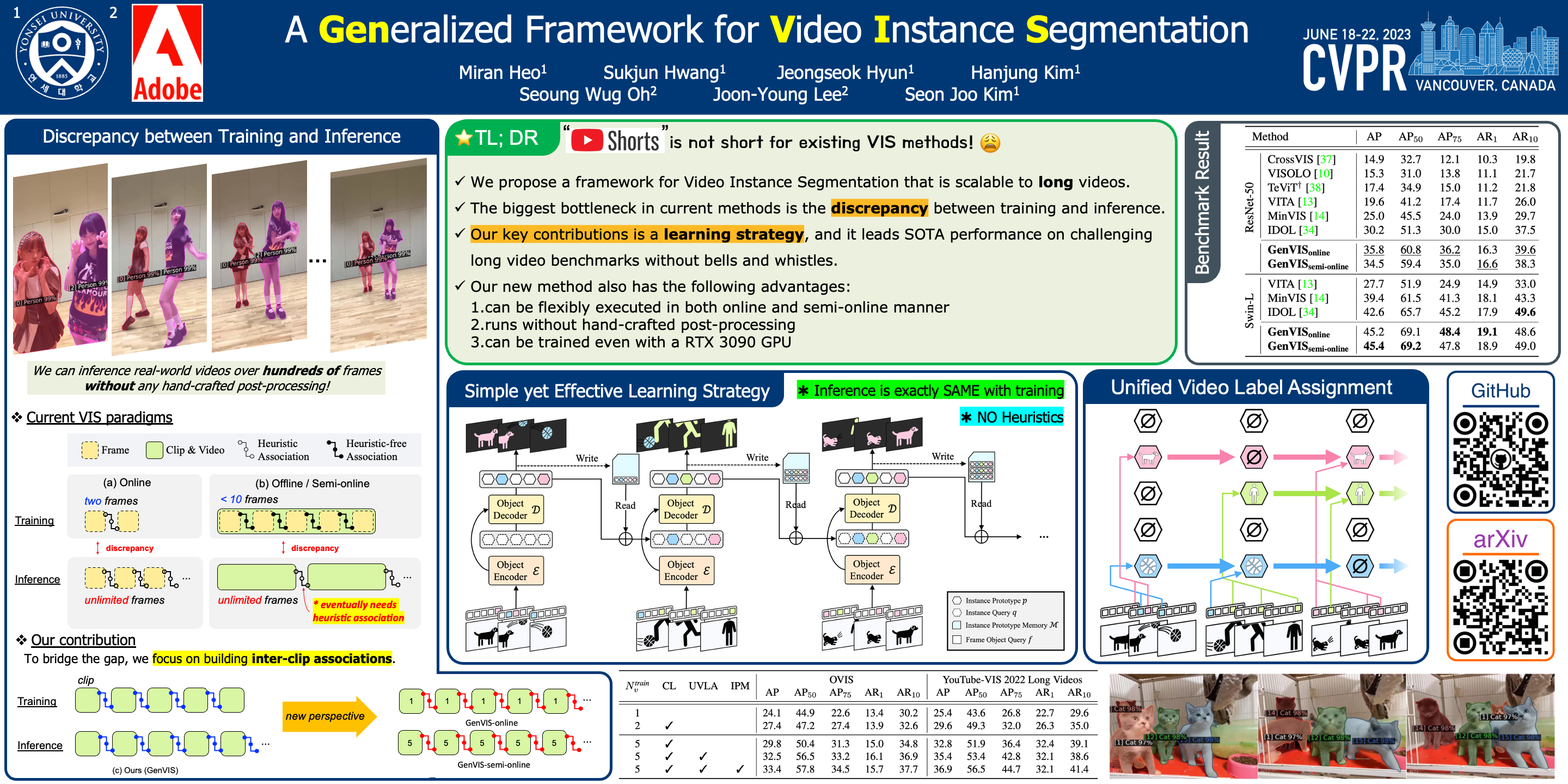
The handling of long videos with complex and occluded sequences has recently emerged as a new challenge in the video instance segmentation (VIS) community. However, existing methods have limitations in addressing this challenge. We argue that the biggest bottleneck in current approaches is the discrepancy between training and inference. To effectively bridge this gap, we propose a Generalized framework for VIS, namely GenVIS, that achieves state-of-the-art performance on challenging benchmarks without designing complicated architectures or requiring extra post-processing. The key contribution of GenVIS is the learning strategy, which includes a query-based training pipeline for sequential learning with a novel target label assignment. Additionally, we introduce a memory that effectively acquires information from previous states. Thanks to the new perspective, which focuses on building relationships between separate frames or clips, GenVIS can be flexibly executed in both online and semi-online manner. We evaluate our approach on popular VIS benchmarks, achieving state-of-the-art results on YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS). Notably, we greatly outperform the state-of-the-art on the long VIS benchmark (OVIS), improving 5.6 AP with ResNet-50 backbone. Code is available at https://github.com/miranheo/GenVIS.