Siamese Image Modeling for Self-Supervised Vision Representation Learning
{kind=link}
Abstract
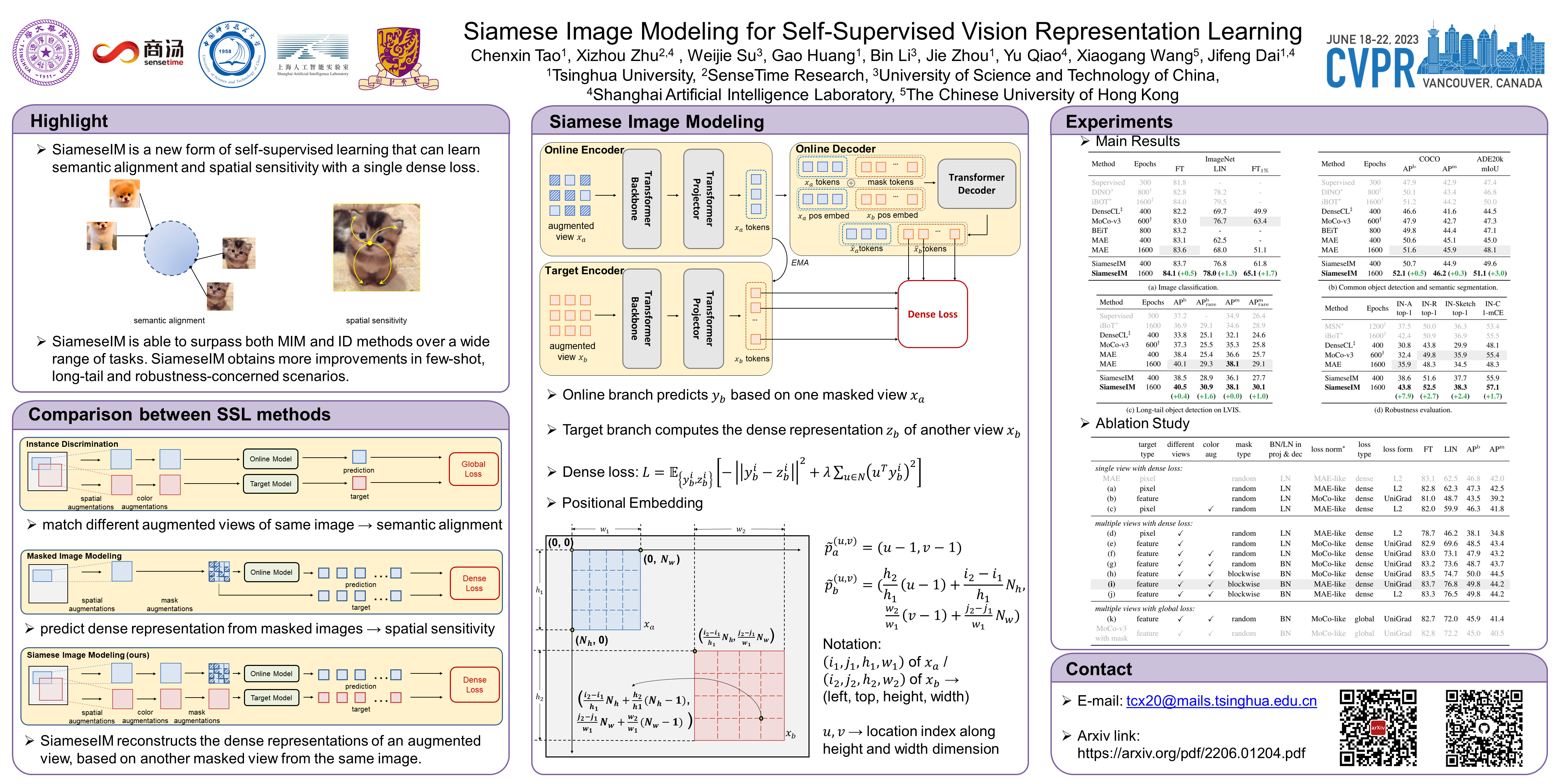
Self-supervised learning (SSL) has delivered superior performance on a variety of downstream vision tasks. Two main-stream SSL frameworks have been proposed, i.e., Instance Discrimination (ID) and Masked Image Modeling (MIM). ID pulls together representations from different views of the same image, while avoiding feature collapse. It lacks spatial sensitivity, which requires modeling the local structure within each image. On the other hand, MIM reconstructs the original content given a masked image. It instead does not have good semantic alignment, which requires projecting semantically similar views into nearby representations. To address this dilemma, we observe that (1) semantic alignment can be achieved by matching different image views with strong augmentations; (2) spatial sensitivity can benefit from predicting dense representations with masked images. Driven by these analysis, we propose Siamese Image Modeling (SiameseIM), which predicts the dense representations of an augmented view, based on another masked view from the same image but with different augmentations. SiameseIM uses a Siamese network with two branches. The online branch encodes the first view, and predicts the second view’s representation according to the relative positions between these two views. The target branch produces the target by encoding the second view. SiameseIM can surpass both ID and MIM on a wide range of downstream tasks, including ImageNet finetuning and linear probing, COCO and LVIS detection, and ADE20k semantic segmentation. The improvement is more significant in few-shot, long-tail and robustness-concerned scenarios. Code shall be released.