Perception-Oriented Single Image Super-Resolution Using Optimal Objective Estimation
{kind=link}
Abstract
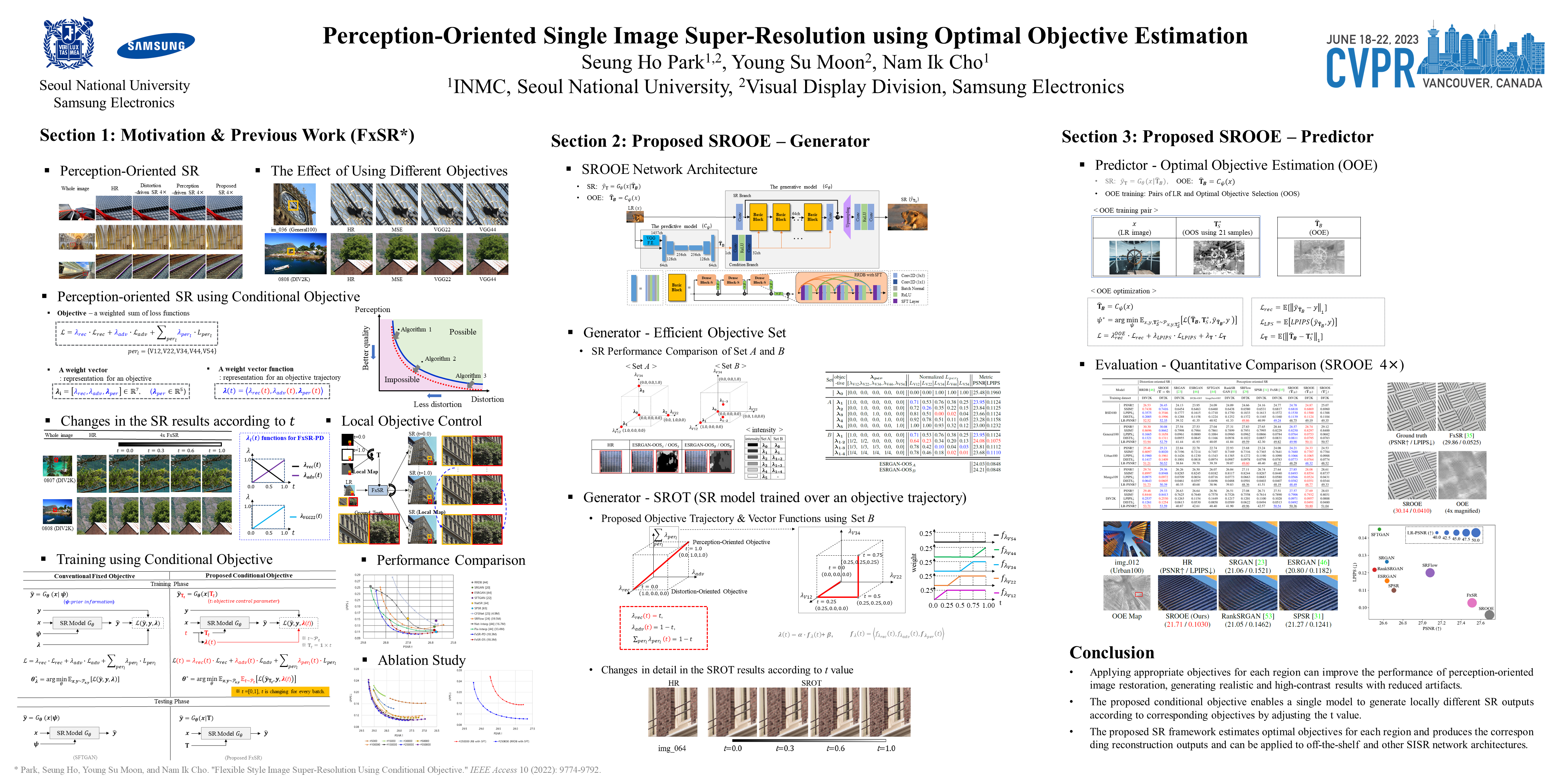
Single-image super-resolution (SISR) networks trained with perceptual and adversarial losses provide high-contrast outputs compared to those of networks trained with distortion-oriented losses, such as L1 or L2. However, it has been shown that using a single perceptual loss is insufficient for accurately restoring locally varying diverse shapes in images, often generating undesirable artifacts or unnatural details. For this reason, combinations of various losses, such as perceptual, adversarial, and distortion losses, have been attempted, yet it remains challenging to find optimal combinations. Hence, in this paper, we propose a new SISR framework that applies optimal objectives for each region to generate plausible results in overall areas of high-resolution outputs. Specifically, the framework comprises two models: a predictive model that infers an optimal objective map for a given low-resolution (LR) input and a generative model that applies a target objective map to produce the corresponding SR output. The generative model is trained over our proposed objective trajectory representing a set of essential objectives, which enables the single network to learn various SR results corresponding to combined losses on the trajectory. The predictive model is trained using pairs of LR images and corresponding optimal objective maps searched from the objective trajectory. Experimental results on five benchmarks show that the proposed method outperforms state-of-the-art perception-driven SR methods in LPIPS, DISTS, PSNR, and SSIM metrics. The visual results also demonstrate the superiority of our method in perception-oriented reconstruction. The code is available at https://github.com/seungho-snu/SROOE.