EC2: Emergent Communication for Embodied Control
{kind=link}
Abstract
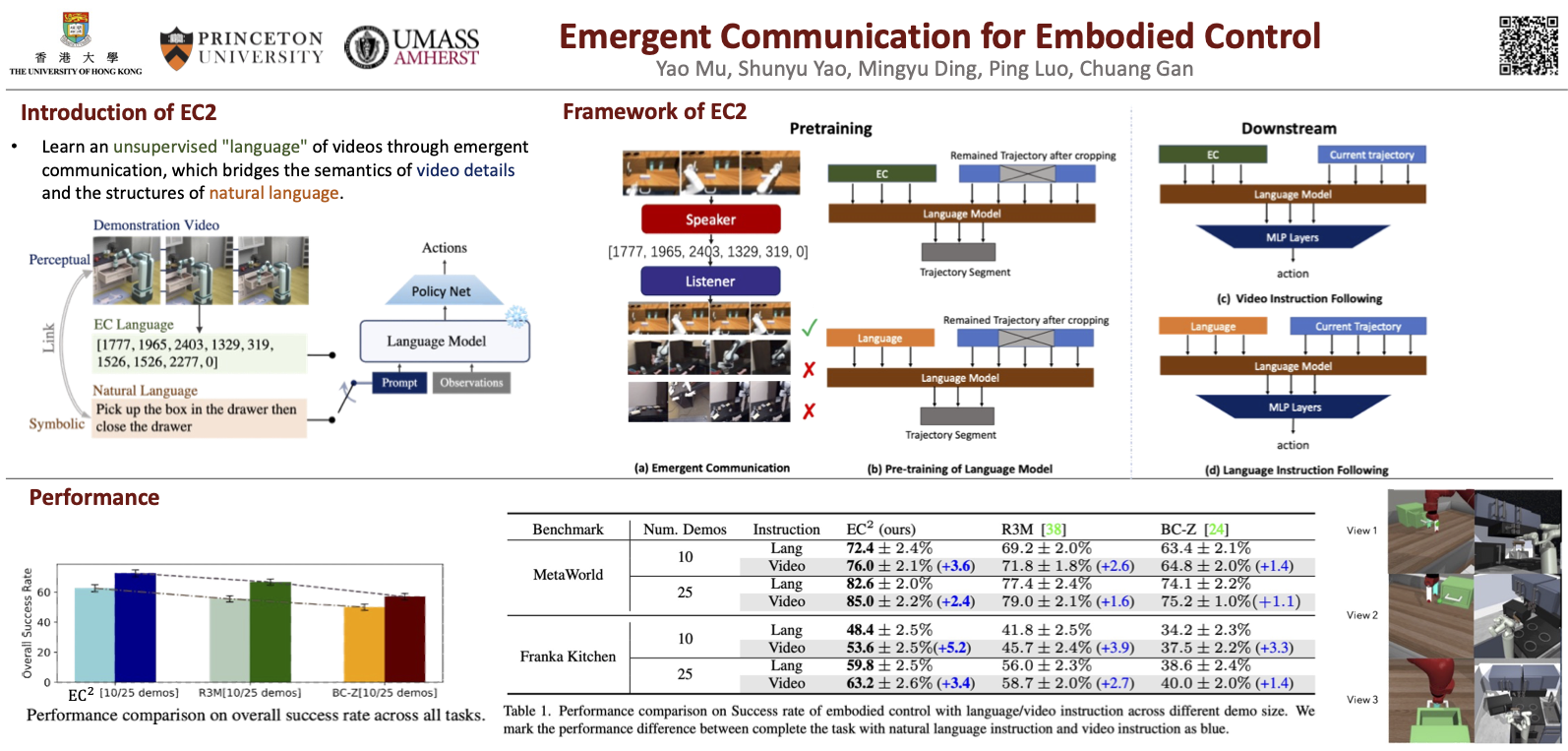
Embodied control requires agents to leverage multi-modal pre-training to quickly learn how to act in new environments, where video demonstrations contain visual and motion details needed for low-level perception and control, and language instructions support generalization with abstract, symbolic structures. While recent approaches apply contrastive learning to force alignment between the two modalities, we hypothesize better modeling their complementary differences can lead to more holistic representations for downstream adaption. To this end, we propose Emergent Communication for Embodied Control (EC^2), a novel scheme to pre-train video-language representations for few-shot embodied control. The key idea is to learn an unsupervised “language” of videos via emergent communication, which bridges the semantics of video details and structures of natural language. We learn embodied representations of video trajectories, emergent language, and natural language using a language model, which is then used to finetune a lightweight policy network for downstream control. Through extensive experiments in Metaworld and Franka Kitchen embodied benchmarks, EC^2 is shown to consistently outperform previous contrastive learning methods for both videos and texts as task inputs. Further ablations confirm the importance of the emergent language, which is beneficial for both video and language learning, and significantly superior to using pre-trained video captions. We also present a quantitative and qualitative analysis of the emergent language and discuss future directions toward better understanding and leveraging emergent communication in embodied tasks.