Clover: Towards a Unified Video-Language Alignment and Fusion Model
{kind=link}
Abstract
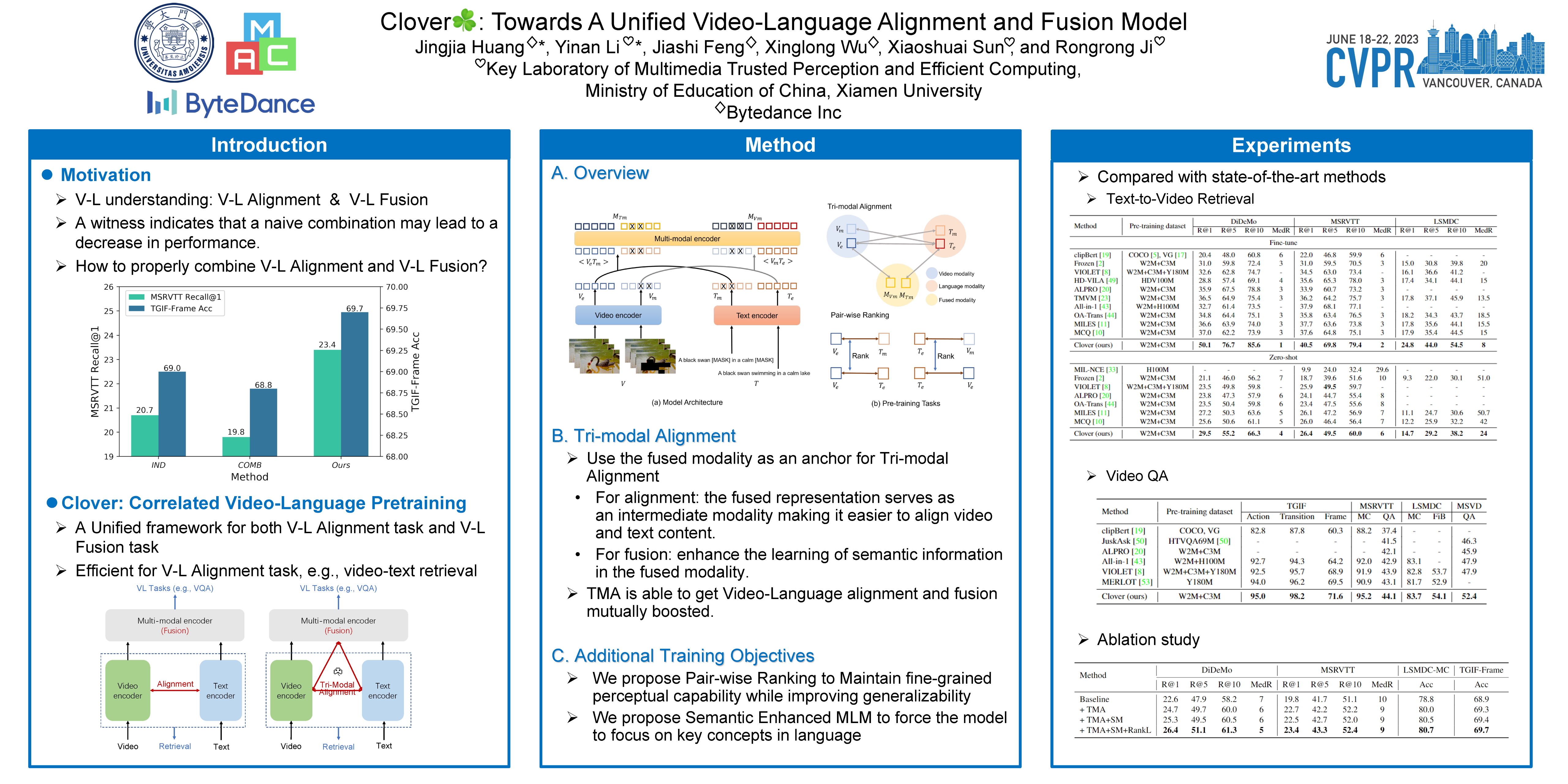
Building a universal video-language model for solving various video understanding tasks (e.g., text-video retrieval, video question answering) is an open challenge to the machine learning field. Towards this goal, most recent works build the model by stacking uni-modal and cross-modal feature encoders and train it with pair-wise contrastive pre-text tasks. Though offering attractive generality, the resulted models have to compromise between efficiency and performance. They mostly adopt different architectures to deal with different downstream tasks. We find this is because the pair-wise training cannot well align and fuse features from different modalities. We then introduce Clover--a Correlated Video-Language pre-training method--towards a universal video-language model for solving multiple video understanding tasks with neither performance nor efficiency compromise. It improves cross-modal feature alignment and fusion via a novel tri-modal alignment pre-training task. Additionally, we propose to enhance the tri-modal alignment via incorporating learning from semantic masked samples and a new pair-wise ranking loss. Clover establishes new state-of-the-arts on multiple downstream tasks, including three retrieval tasks for both zero-shot and fine-tuning settings, and eight video question answering tasks. Codes and pre-trained models will be released at https://github.com/LeeYN-43/Clover.