Vision Transformers Are Parameter-Efficient Audio-Visual Learners
{kind=link}
Abstract
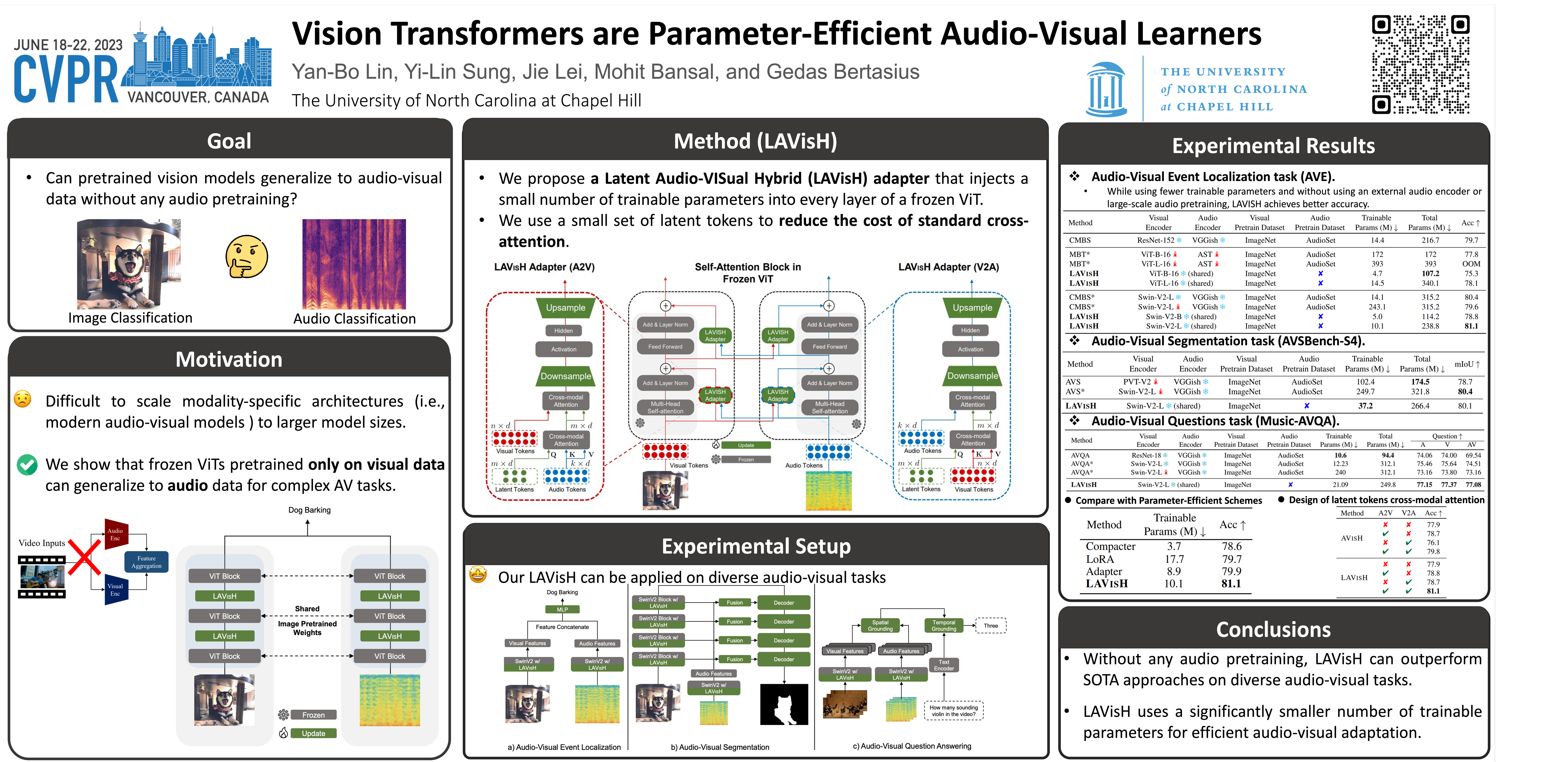
Vision transformers (ViTs) have achieved impressive results on various computer vision tasks in the last several years. In this work, we study the capability of frozen ViTs, pretrained only on visual data, to generalize to audio-visual data without finetuning any of its original parameters. To do so, we propose a latent audio-visual hybrid (LAVISH) adapter that adapts pretrained ViTs to audio-visual tasks by injecting a small number of trainable parameters into every layer of a frozen ViT. To efficiently fuse visual and audio cues, our LAVISH adapter uses a small set of latent tokens, which form an attention bottleneck, thus, eliminating the quadratic cost of standard cross-attention. Compared to the existing modality-specific audio-visual methods, our approach achieves competitive or even better performance on various audio-visual tasks while using fewer tunable parameters and without relying on costly audio pretraining or external audio encoders. Our code is available at https://genjib.github.io/project_page/LAVISH/