BEV@DC: Bird’s-Eye View Assisted Training for Depth Completion
{kind=link}
Abstract
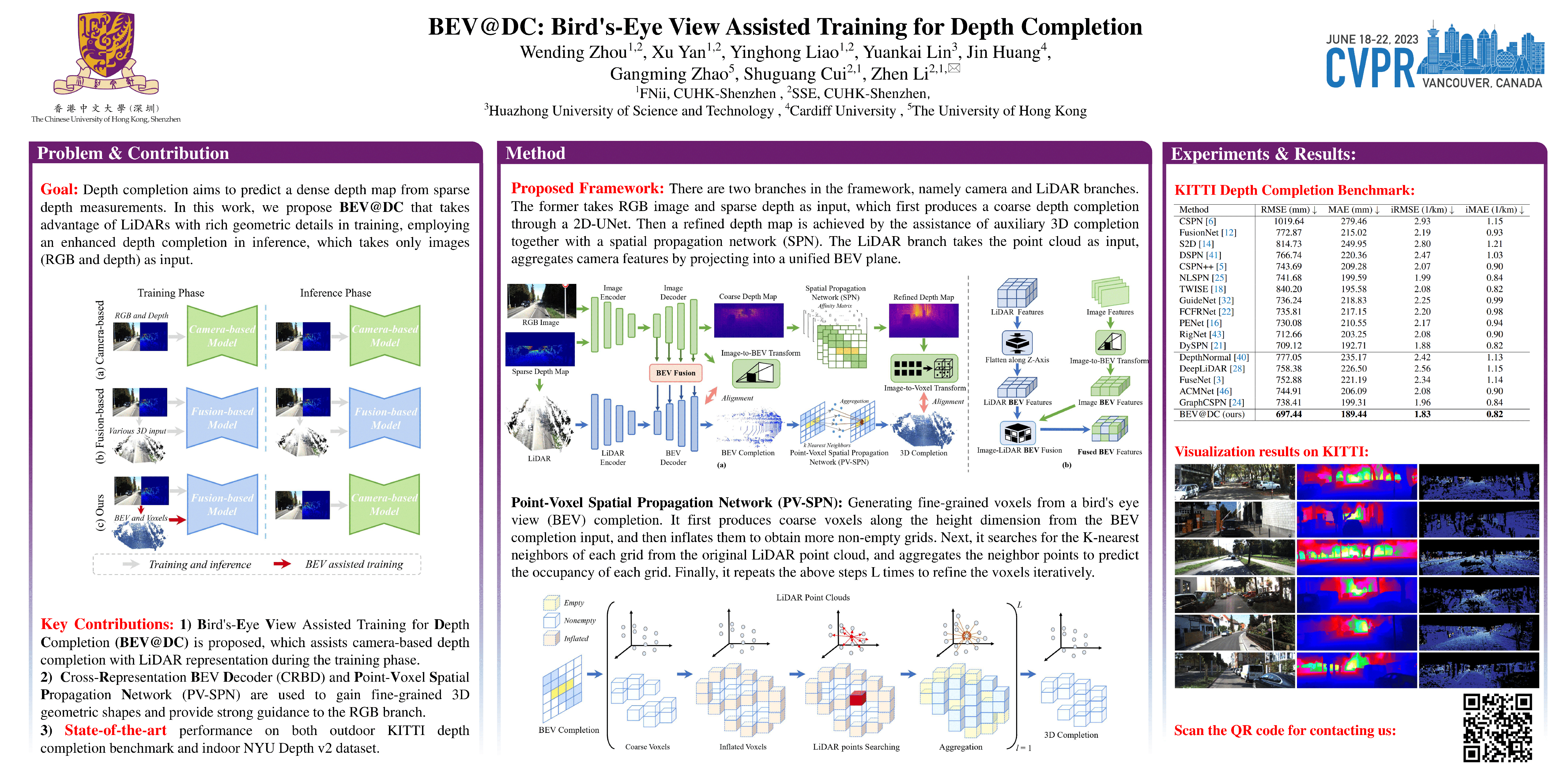
Depth completion plays a crucial role in autonomous driving, in which cameras and LiDARs are two complementary sensors. Recent approaches attempt to exploit spatial geometric constraints hidden in LiDARs to enhance image-guided depth completion. However, only low efficiency and poor generalization can be achieved. In this paper, we propose BEV@DC, a more efficient and powerful multi-modal training scheme, to boost the performance of image-guided depth completion. In practice, the proposed BEV@DC model comprehensively takes advantage of LiDARs with rich geometric details in training, employing an enhanced depth completion manner in inference, which takes only images (RGB and depth) as input. Specifically, the geometric-aware LiDAR features are projected onto a unified BEV space, combining with RGB features to perform BEV completion. By equipping a newly proposed point-voxel spatial propagation network (PV-SPN), this auxiliary branch introduces strong guidance to the original image branches via 3D dense supervision and feature consistency. As a result, our baseline model demonstrates significant improvements with the sole image inputs. Concretely, it achieves state-of-the-art on several benchmarks, e.g., ranking Top-1 on the challenging KITTI depth completion benchmark.