Object Pop-Up: Can We Infer 3D Objects and Their Poses From Human Interactions Alone?
{kind=link}
Abstract
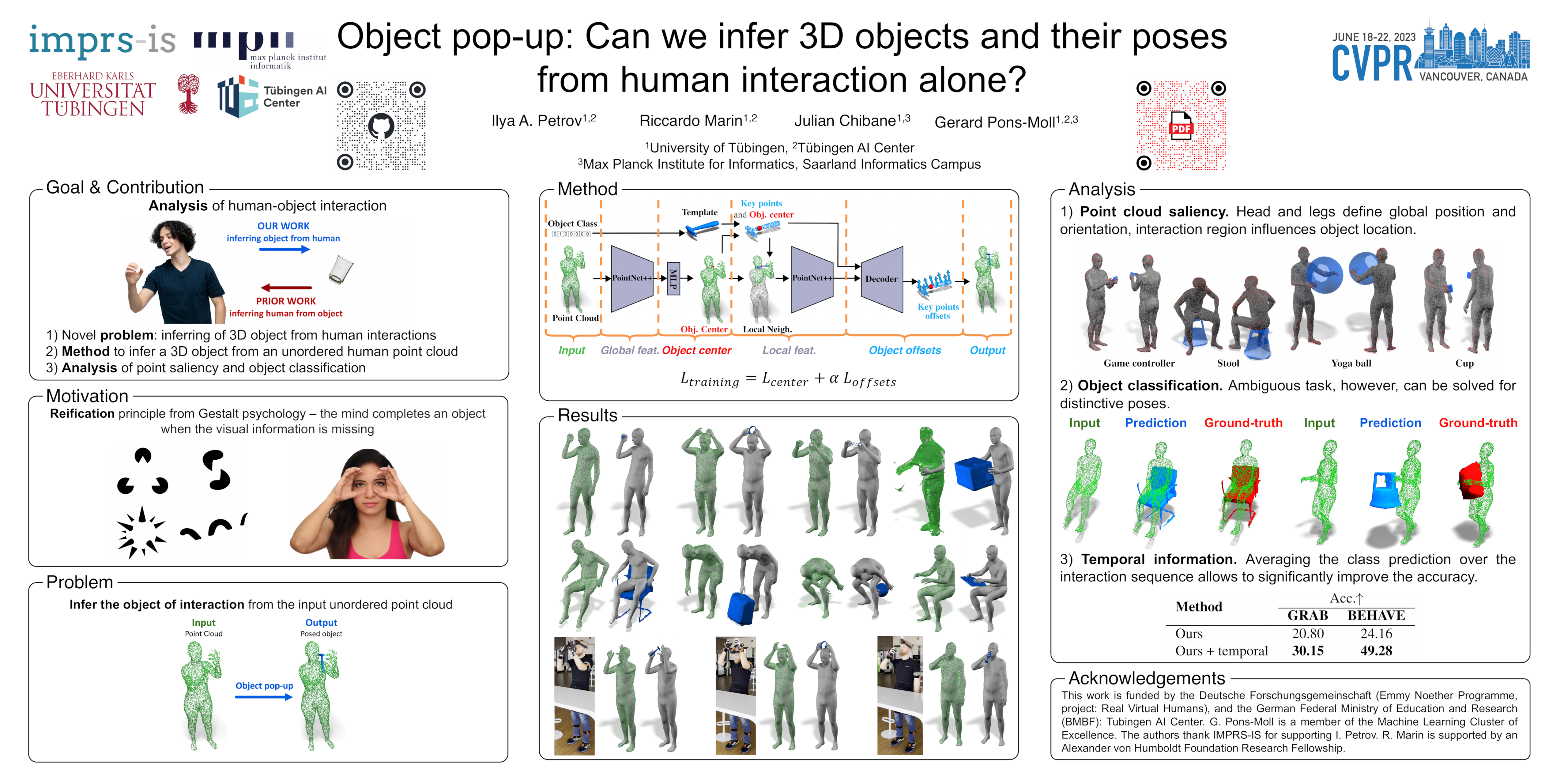
The intimate entanglement between objects affordances and human poses is of large interest, among others, for behavioural sciences, cognitive psychology, and Computer Vision communities. In recent years, the latter has developed several object-centric approaches: starting from items, learning pipelines synthesizing human poses and dynamics in a realistic way, satisfying both geometrical and functional expectations. However, the inverse perspective is significantly less explored: Can we infer 3D objects and their poses from human interactions alone? Our investigation follows this direction, showing that a generic 3D human point cloud is enough to pop up an unobserved object, even when the user is just imitating a functionality (e.g., looking through a binocular) without involving a tangible counterpart. We validate our method qualitatively and quantitatively, with synthetic data and sequences acquired for the task, showing applicability for XR/VR.