Random Entangled Tokens for Adversarially Robust Vision Transformer
{kind=link}
Abstract
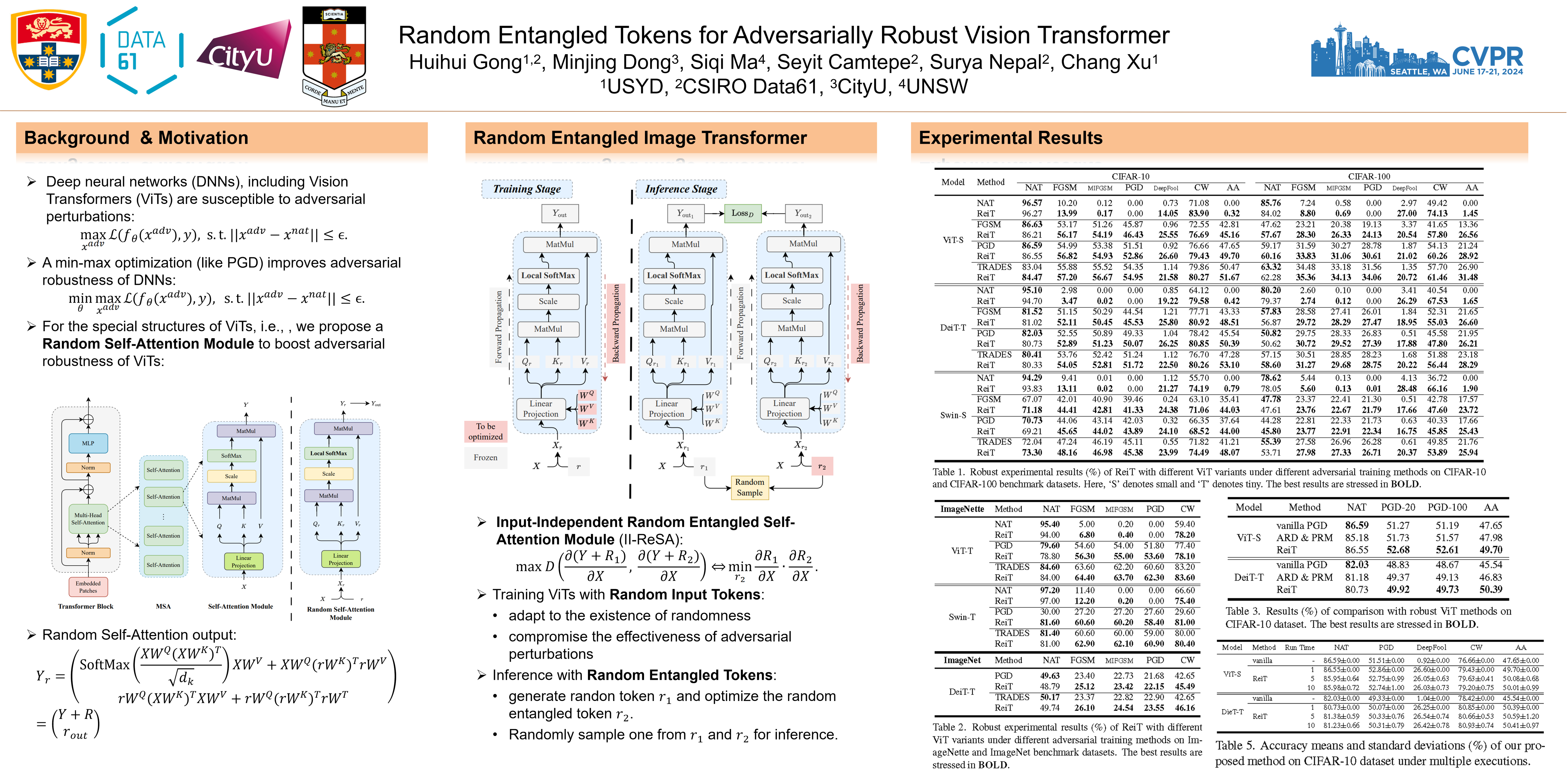
Vision Transformers (ViTs) have emerged as a compelling alternative to Convolutional Neural Networks (CNNs) in the realm of computer vision, showcasing tremendous potential. However, recent research has unveiled a susceptibility of ViTs to adversarial attacks, akin to their CNN counterparts. Adversarial training and randomization are two representative effective defenses for CNNs. Some researchers have attempted to apply adversarial training to ViTs and achieved comparable robustness to CNNs, while it is not easy to directly apply randomization to ViTs because of the architecture difference between CNNs and ViTs. In this paper, we delve into the structural intricacies of ViTs and propose a novel defense mechanism termed Random entangled image Transformer (ReiT), which seamlessly integrates adversarial training and randomization to bolster the adversarial robustness of ViTs. Recognizing the challenge posed by the structural disparities between ViTs and CNNs, we introduce a novel module, input-independent random entangled self-attention (II-ReSA). This module optimizes random entangled tokens that lead to "dissimilar" self-attention outputs by leveraging model parameters and the sampled random tokens, thereby synthesizing the self-attention module outputs and random entangled tokens to diminish adversarial similarity. ReiT incorporates two distinct random entangled tokens and employs dual randomization, offering an effective countermeasure against adversarial examples while ensuring comprehensive deduction guarantees. Through extensive experiments conducted on various ViT variants and benchmarks, we substantiate the superiority of our proposed method in enhancing the adversarial robustness of Vision Transformers.