Active Open-Vocabulary Recognition: Let Intelligent Moving Mitigate CLIP Limitations
{kind=link}
Abstract
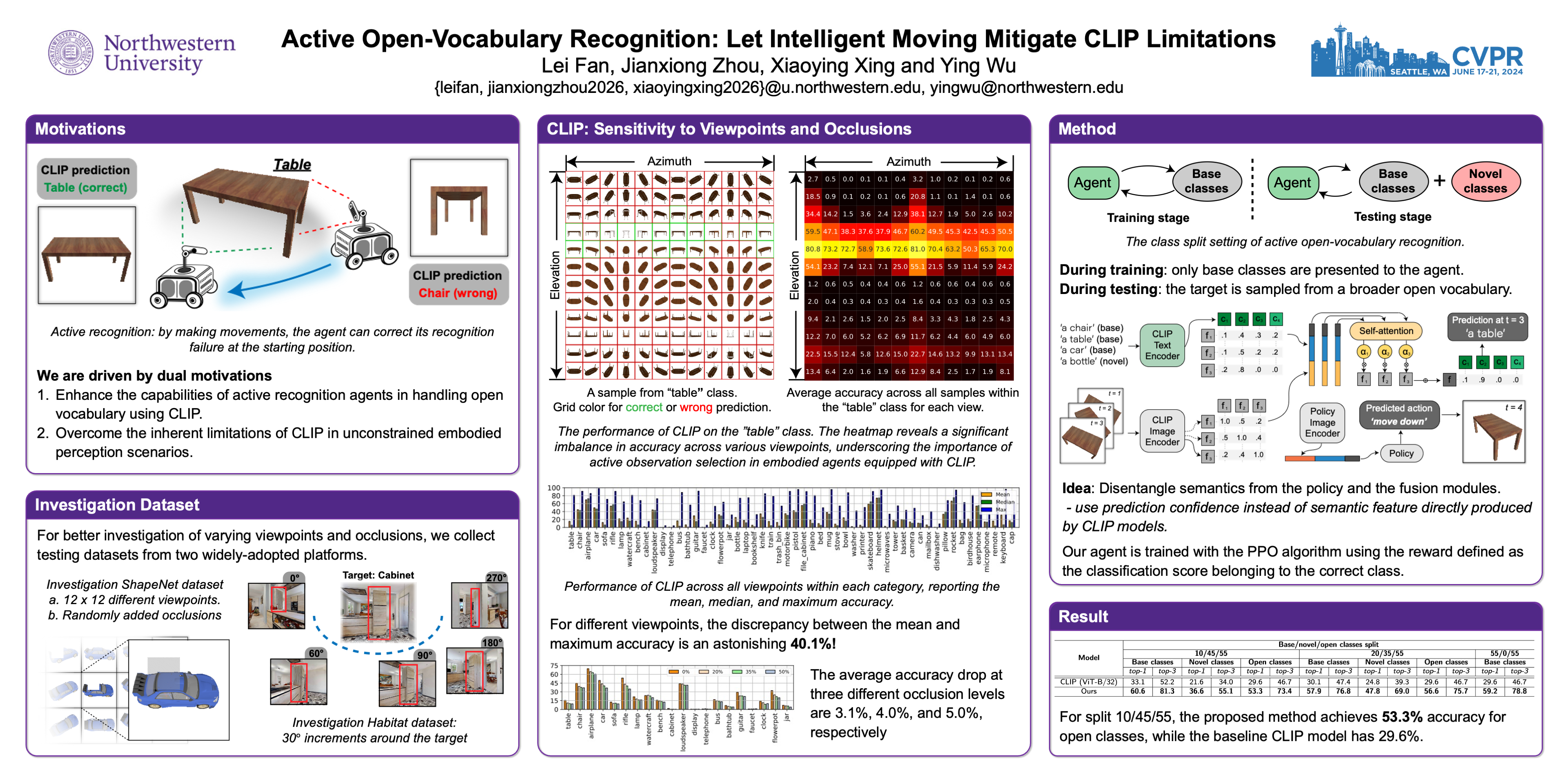
Active recognition, which allows intelligent agents to explore observations for better recognition performance, serves as a prerequisite for various embodied AI tasks, such as grasping, navigation and room arrangements. Given the evolving environment and the multitude of object classes, it is impractical to include all possible classes during the training stage. In this paper, we aim at advancing active open-vocabulary recognition, empowering embodied agents to actively perceive and classify arbitrary objects. However, directly adopting recent open-vocabulary classification models, like Contrastive Language Image Pretraining (CLIP), poses its unique challenges. Specifically, we observe that CLIP's performance is heavily affected by the viewpoint and occlusions, compromising its reliability in unconstrained embodied perception scenarios. Further, the sequential nature of observations in agent-environment interactions necessitates an effective method for integrating features that maintains discriminative strength for open-vocabulary classification. To address these issues, we introduce a novel agent for active open-vocabulary recognition. The proposed method leverages inter-frame and inter-concept similarities to navigate agent movements and to fuse features, without relying on class-specific knowledge. Compared to baseline CLIP model with 29.6\% accuracy on ShapeNet dataset, the proposed agent could achieve 53.3\% accuracy for open-vocabulary recognition, without any fine-tuning to the equipped CLIP model. Additional experiments conducted with the Habitat simulator further affirm the efficacy of our method.