TIGER: Time-Varying Denoising Model for 3D Point Cloud Generation with Diffusion Process
{kind=link}
Abstract
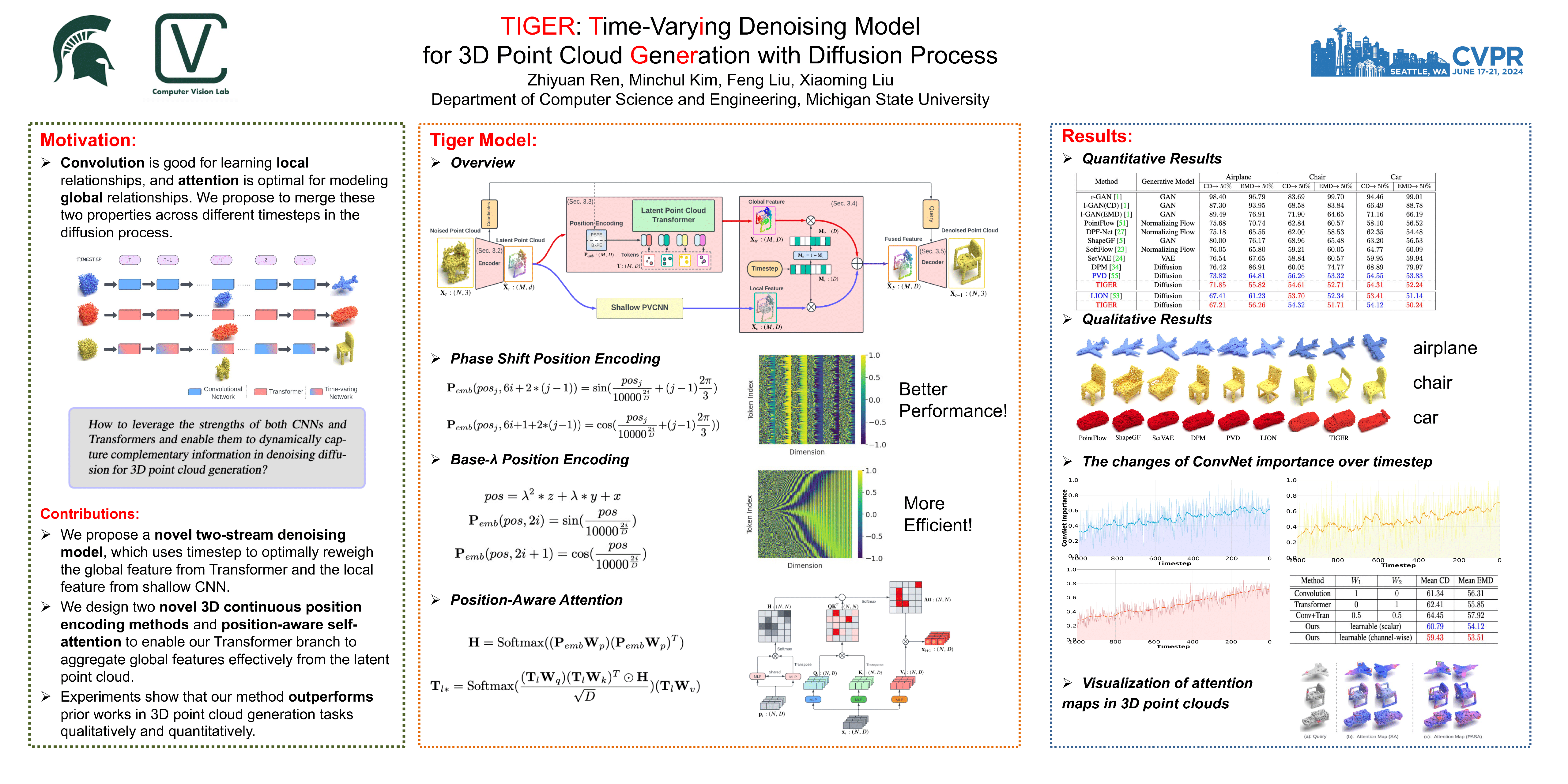
Recently, diffusion models have emerged as a new pow-erful generative method for 3D point cloud generationtasks. However, few works study the effect of the architec-ture of the diffusion model in the 3D point cloud, resortingto the typical UNet model developed for 2D images. In-spired by the wide adoption of Transformers, we study thecomplementary role of convolution (from UNet) and atten-tion (from Transformers). We discover that their respectiveimportance change according to the timestep in the diffu-sion process. At an early stage, the attention is given alarger weight to generate the overall shape quickly, andat a later stage, the convolution has a larger weight to re-fine the local surface’s quality of the generated point cloud.We propose a time-varying two-stream denoising modelcombined with convolution layers and transformer blocks.We generate an optimizable mask from each timestep toreweigh global and local features, obtaining time-varyingfused features. Experimentally, we demonstrate that ourproposed method quantitatively outperforms other state-of-the-art methods regarding visual quality and diversity. Thecode and models will be released upon publication.