Free3D: Consistent Novel View Synthesis without 3D Representation
{kind=link}
Abstract
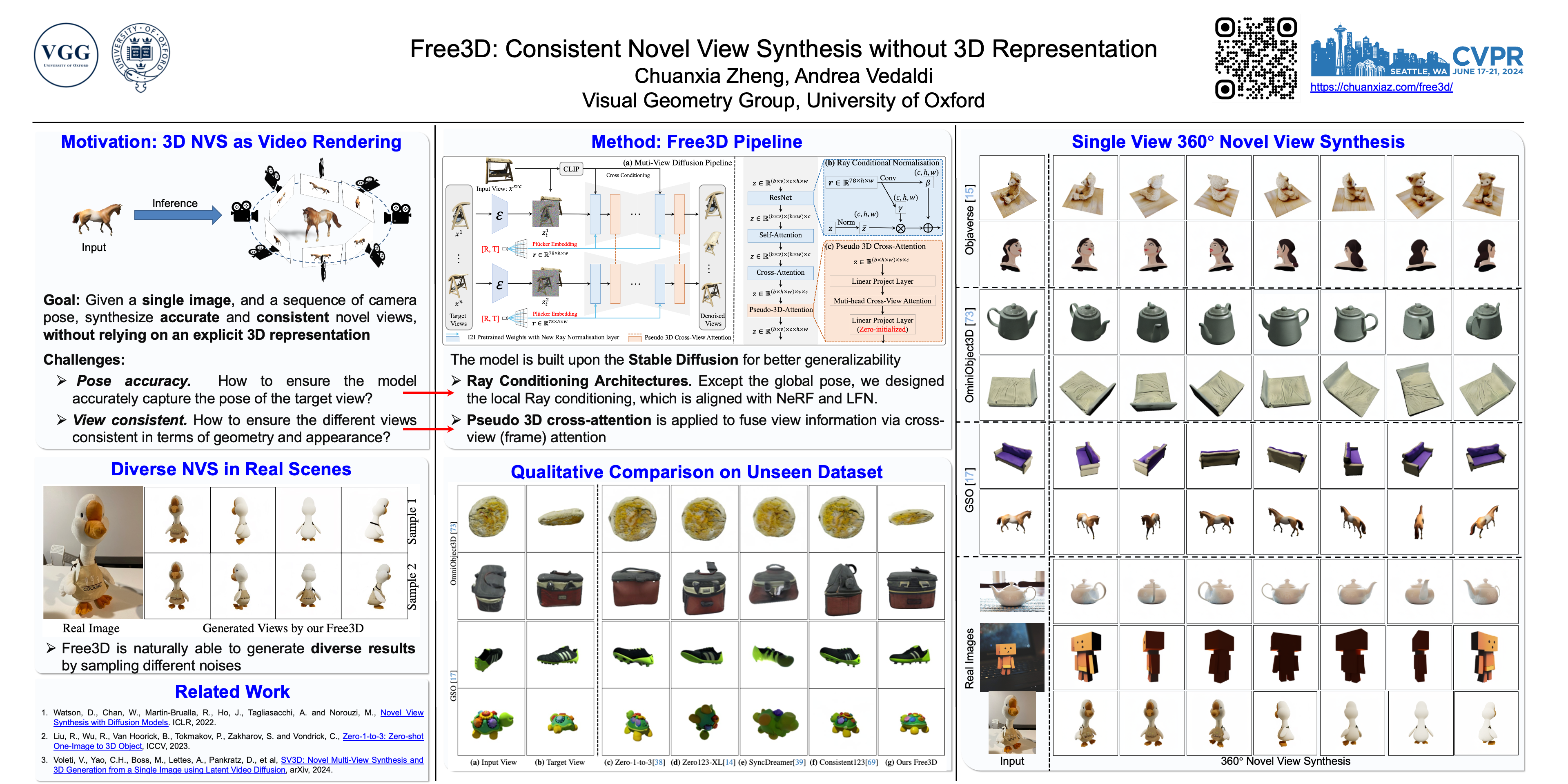
We introduce Free3D, a simple accurate method for monocular open-set novel view synthesis (NVS). Similar to Zero-1-to-3, we start from a pre-trained 2D image generator for generalization, and fine-tune it for NVS. Compared to other works that took a similar approach, we obtain significant improvements without resorting to an explicit 3D representation, which is slow and memory-consuming, andwithout training an additional network for 3D reconstruction. Our key contribution is to improve the way the target camera pose is encoded in the network, which we do by introducing a new ray conditioning normalization (RCN) layer. The latter injects pose information in the underlying 2D image generator by telling each pixel its viewing direction. We further improve multi-view consistency by using light-weight multi-view attention layers and by sharing generation noise between the different views. We train Free3D on the Objaverse dataset and demonstrate excellent generalization to new categories in new datasets, including OmniObject3D and GSO. The project page is available at https://chuanxiaz.com/free3d/.