Video Prediction by Modeling Videos as Continuous Multi-Dimensional Processes
Gaurav Shrivastava ⋅ Abhinav Shrivastava
2024 Poster
{kind=link}
Abstract
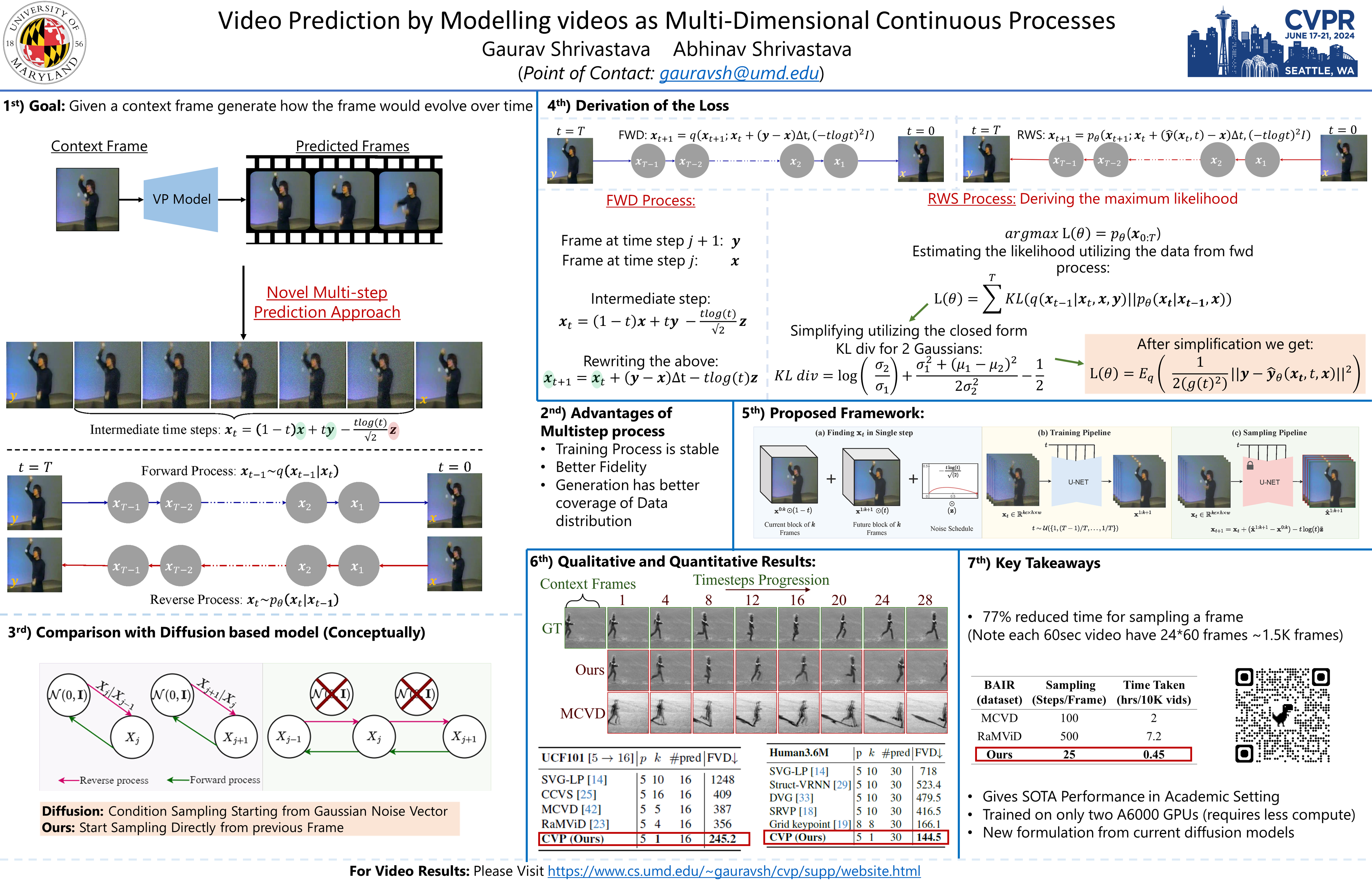
Diffusion models have made significant strides in image generation, mastering tasks such as unconditional image synthesis, text-image translation, and image-to-image conversions. However, their capability falls short in the realm of video prediction, mainly because they treat videos as a collection of independent images, relying on external constraints such as temporal attention mechanism to enforce temporal coherence. In our paper, we introduce a novel model class, that treats video as a continuous multi-dimensional process rather than a series of discrete frames. Through extensive experimentation, we establish state-of-the-art performance in video prediction, validated on benchmark datasets including KTH, BAIR, Human3.6M and UCF101.
Chat is not available.
Successful Page Load