Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers
{kind=link}
Abstract
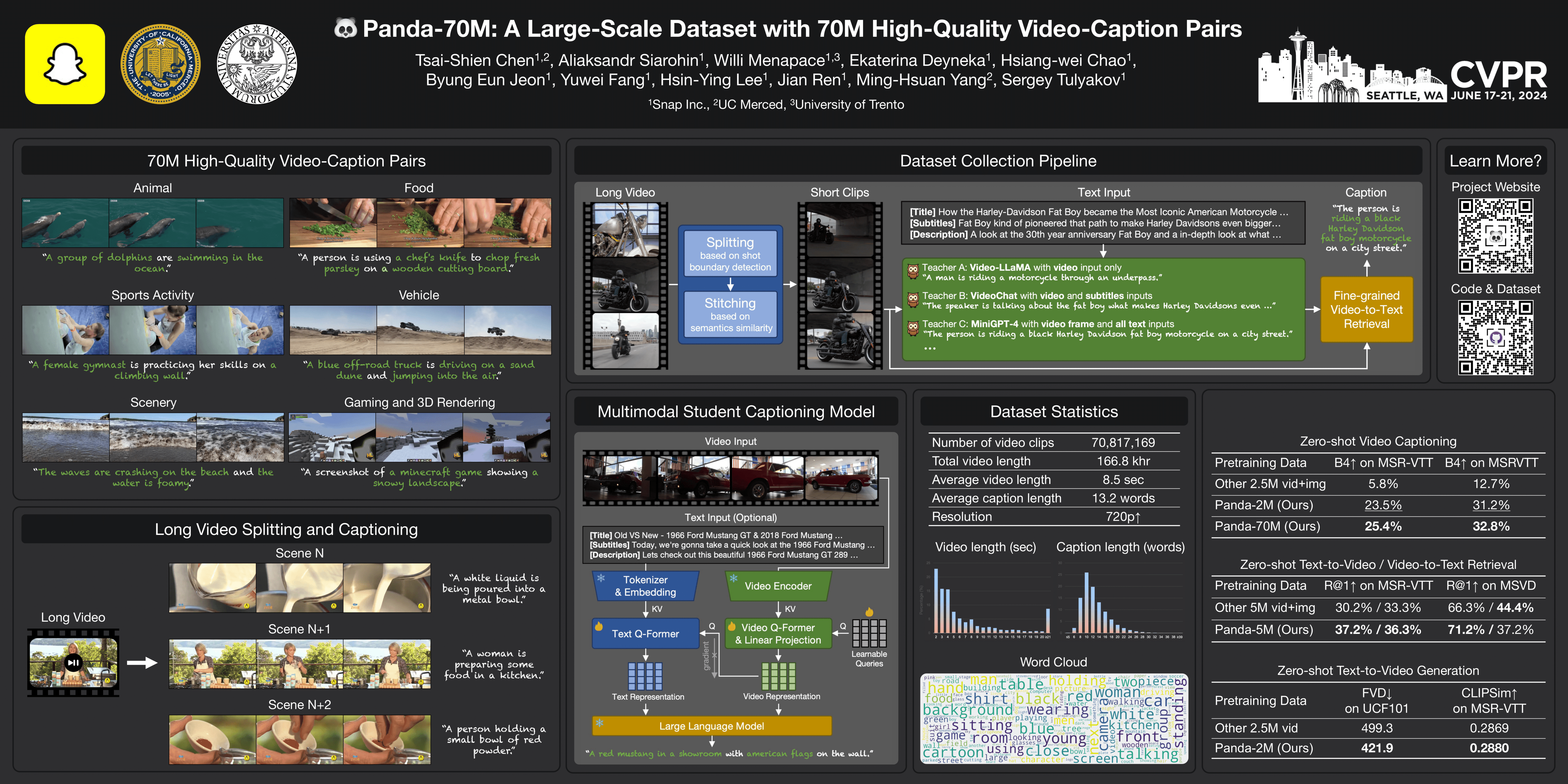
The quality of the data and annotation upper-bounds the quality of a downstream model. While there exist large text corpora and image-text pairs, high-quality video-text data is much harder to collect. First of all, manual labeling is more time-consuming, as it requires an annotator to watch an entire video. Second, videos have a temporal dimension, consist of a number of scenes stacked together, and show multiple actions. Accordingly, to establish a video dataset with high-quality captions, we propose an automatic approach leveraging multimodal inputs, such as textual video description, subtitles, and individual video frames. Specifically, we curate 3.8M high-resolution videos from the publicly available HD-VILA-100M dataset. We then split them into semantically consistent video clips, and apply multiple cross-modality teacher models to obtain captions for each video. Next, we finetune a retrieval model on a small subset where the best caption of each video is manually selected and then employ the model in the whole dataset to select the best caption as the annotation. In this way, we get 70M videos paired with high-quality text captions. We dub the dataset as Panda-70M. We show the value of the proposed dataset on three downstream tasks: video captioning, video and text retrieval, and text-driven video generation. The models trained on the proposed data score substantially better on the majority of metrics across all the tasks.