Matching Anything by Segmenting Anything
 Highlight
Highlight
{kind=link}
Abstract
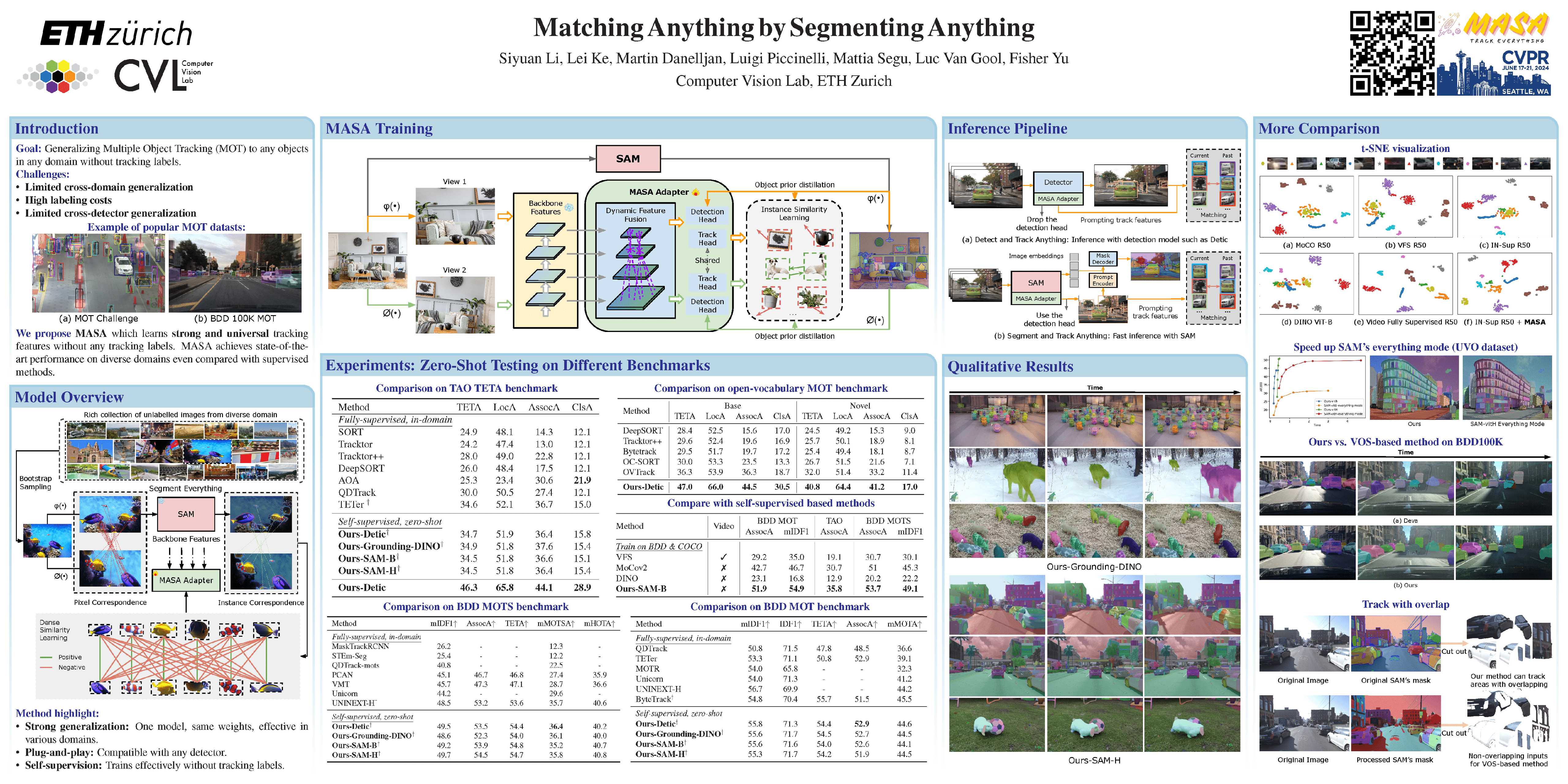
The robust association of the same objects across video frames in complex scenes is crucial for many applications, especially multiple object tracking (MOT). Current methods predominantly rely on labeled domain-specific video datasets, which limits the cross-domain generalization of learned similarity embeddings.We propose MASA, a novel method for robust instance association learning, capable of matching any objects within videos across diverse domains without tracking labels. Leveraging the rich object segmentation from the Segment Anything Model (SAM), MASA learns instance-level correspondence through exhaustive data transformations. We treat the SAM outputs as dense object region proposals and learn to match those regions from a vast image collection.We further design a universal MASA adapter which can work in tandem with foundational segmentation or detection models and enable them to track any detected objects. Those combinations present strong zero-shot tracking ability in complex domains.Extensive tests on multiple challenging MOT and MOTS benchmarks indicate that the proposed method, using only unlabelled static images, achieves even better performance than state-of-the-art methods trained with fully annotated in-domain video sequences, in zero-shot association. Our code is available at https://github.com/siyuanliii/masa.