BigGait: Learning Gait Representation You Want by Large Vision Models
{kind=link}
Abstract
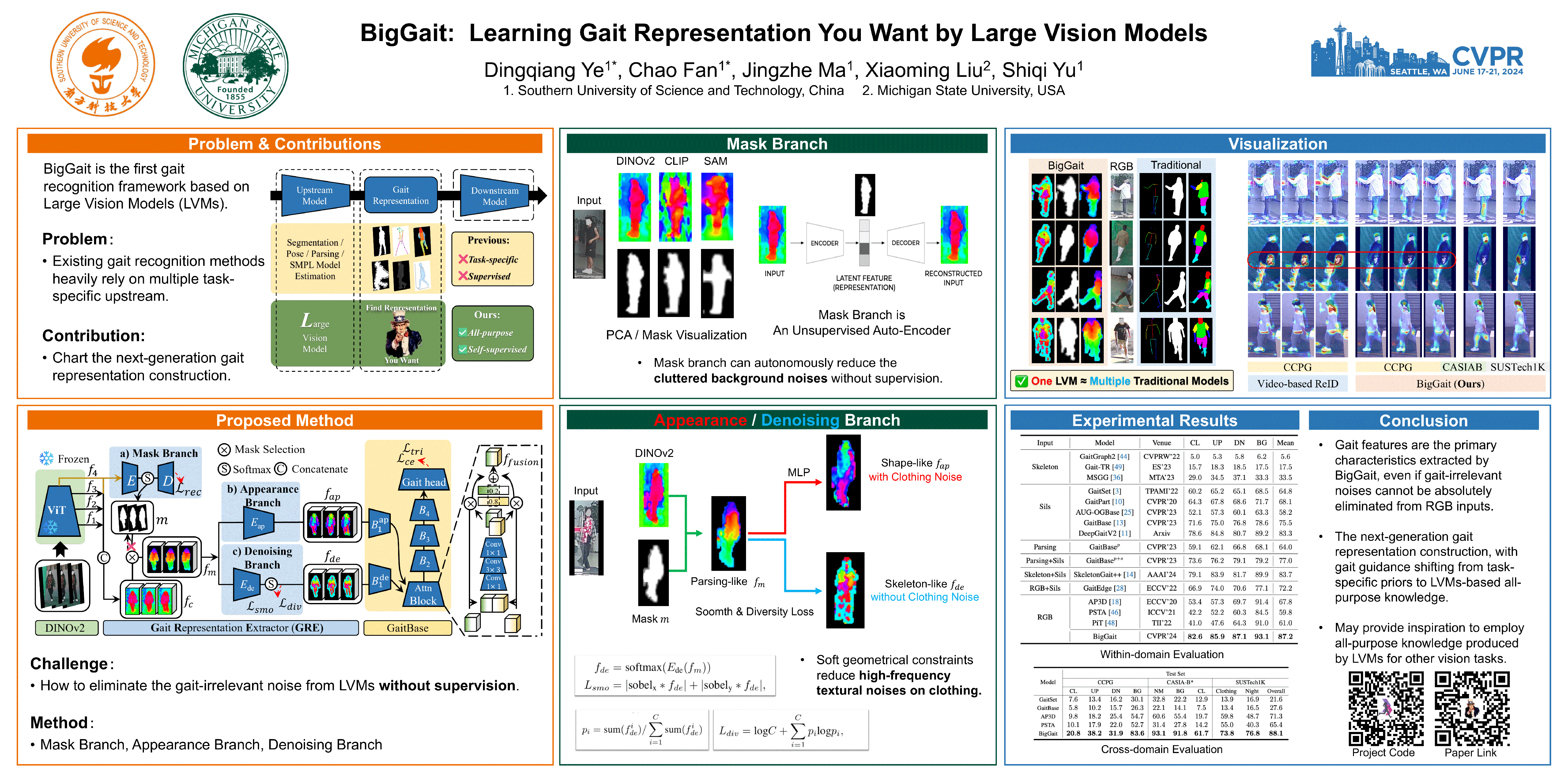
Gait recognition stands as one of the most pivotal remote identification technologies and progressively expands across research and industrial communities. However, existing gait recognition methods heavily rely on task-specific upstream driven by supervised learning to provide explicit gait representations, which inevitably introduce expensive annotation costs and potentially cause cumulative errors. Escaping from this trend, this work explores effective gait representations based on the all-purpose knowledge produced by task-agnostic Large Vision Models (LVMs) and proposes a simple yet efficient gait framework, termed \textbf{BigGait}. Specifically, the Gait Representation Extractor (GRE) in BigGait effectively transforms all-purpose knowledge into implicit gait features in an unsupervised manner, drawing from design principles of established gait representation construction approaches. Experimental results on CCPG, CAISA-B* and SUSTech1K indicate that BigGait significantly outperforms the previous methods in both self-domain and cross-domain tasks in most cases, and provides a more practical paradigm for learning the next-generation gait representation. Eventually, we delve into prospective challenges and promising directions in LVMs-based gait recognition, aiming to inspire future work in this emerging topic. All the source code will be available.