CrossMAE: Cross-Modality Masked Autoencoders for Region-Aware Audio-Visual Pre-Training
{kind=link}
Abstract
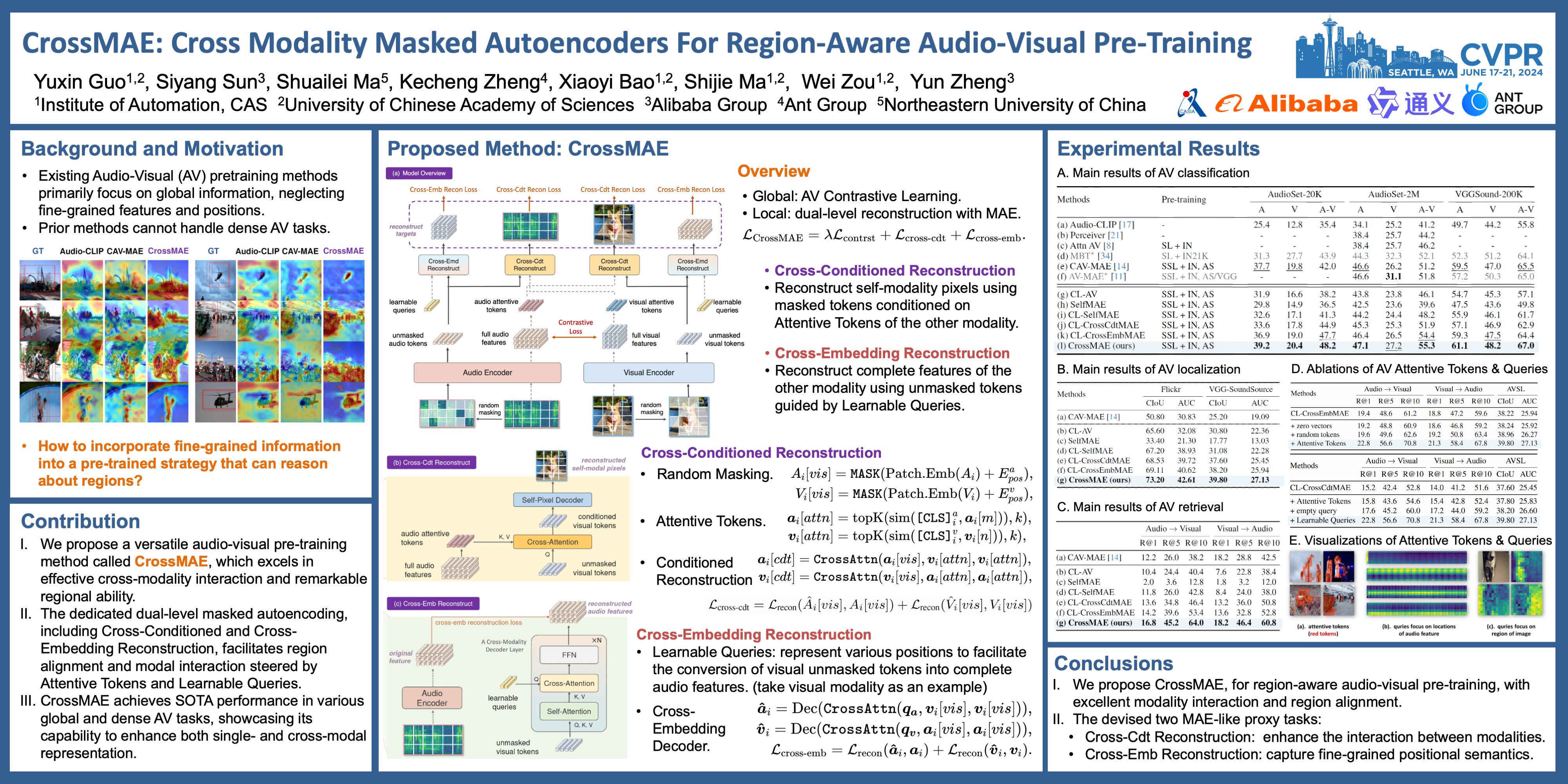
Learning joint and coordinated features across modalities is essential for many audio-visual tasks. Existing pre-training methods primarily focus on global information, neglecting fine-grained features and positions, leading to suboptimal performance in dense prediction tasks. To address this issue, we take a further step towards region-aware audio-visual pre-training and propose CrossMAE, which excels in cross-modality interaction and region alignment. Specifically, we devise two masked autoencoding (MAE) pretext tasks at both pixel and embedding levels, namely Cross-Conditioned Reconstruction and Cross-Embedding Reconstruction. Taking the visual modality as an example (the same goes for audio), in Cross-Conditioned Reconstruction, the visual modality reconstructs the input image pixels conditioned on audio Attentive Tokens. As for the more challenging Cross-Embedding Reconstruction, unmasked visual tokens reconstruct complete audio features under the guidance of learnable queries implying positional information, which effectively enhances the interaction between modalities and exploits fine-grained semantics. Experimental results demonstrate that CrossMAE achieves state-of-the-art performance not only in classification and retrieval, but also in dense prediction tasks. Furthermore, we dive into the mechanism of modal interaction and region alignment of CrossMAE, highlighting the effectiveness of the proposed components.