FFF: Fixing Flawed Foundations in Contrastive Pre-Training Results in Very Strong Vision-Language Models
Adrian Bulat ⋅ Yassine Ouali ⋅ Georgios Tzimiropoulos
2024 Poster
{kind=link}
Abstract
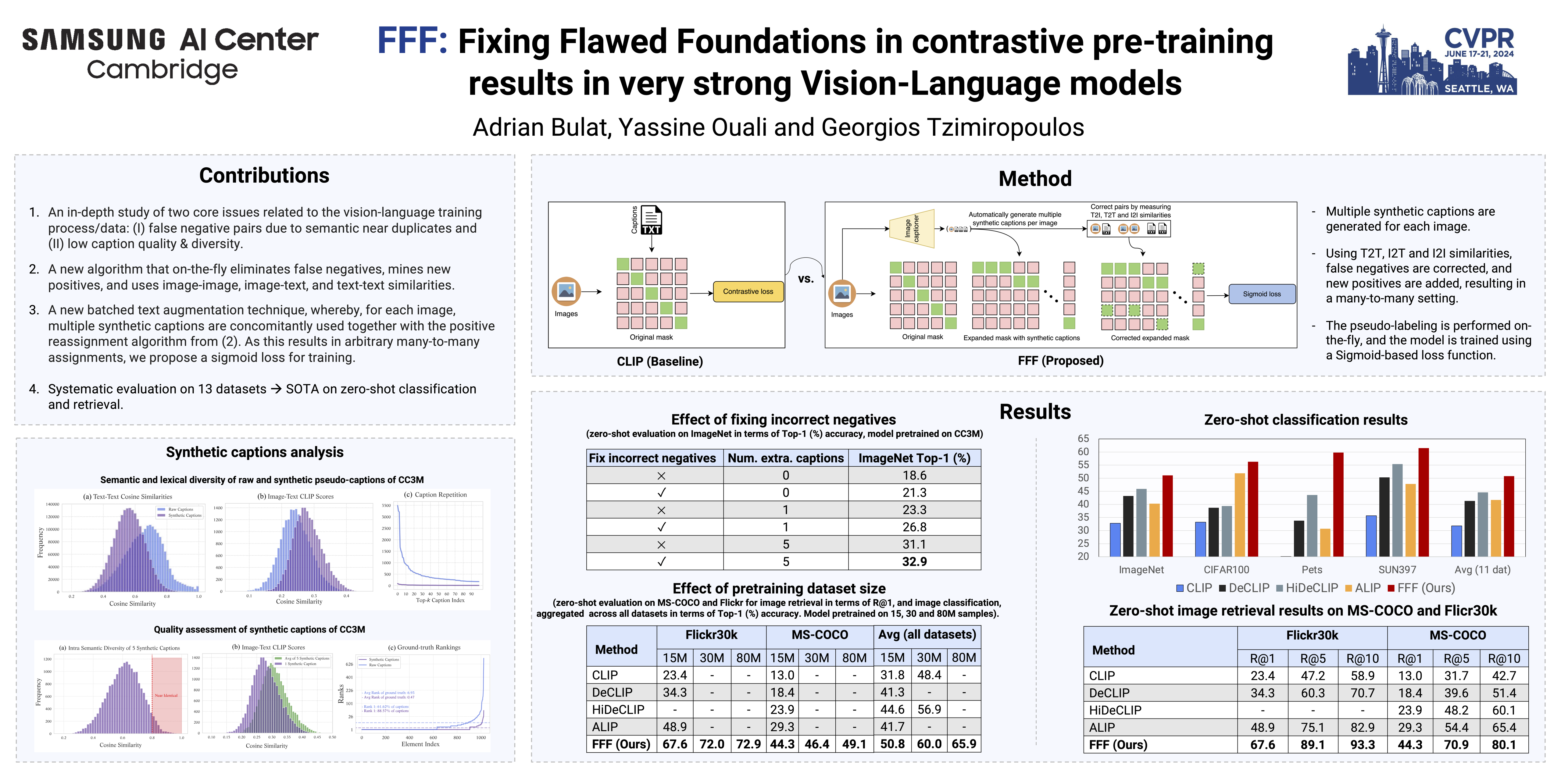
Despite noise and caption quality having been acknowledged as important factors impacting vision-language contrastive pre-training, in this paper, we show that the full potential of improving the training process by addressing such issues is yet to be realized. Specifically, we firstly study and analyze two issues affecting training: incorrect assignment of negative pairs, and low caption quality and diversity. Then, we devise effective solutions for addressing both problems, which essentially require training with multiple true positive pairs. Finally, we propose training with sigmoid loss to address such a requirement. We show very large gains over the current state-of-the-art for both image recognition ($\sim +6\%$ on average over 11 datasets) and image retrieval ($\sim +19\%$ on Flickr30k and $\sim +15\%$ on MSCOCO).
Chat is not available.
Successful Page Load