Convolutional Prompting meets Language Models for Continual Learning
Anurag Roy ⋅ Riddhiman Moulick ⋅ Vinay Verma ⋅ Saptarshi Ghosh ⋅ Abir Das
2024 Poster
{kind=link}
Abstract
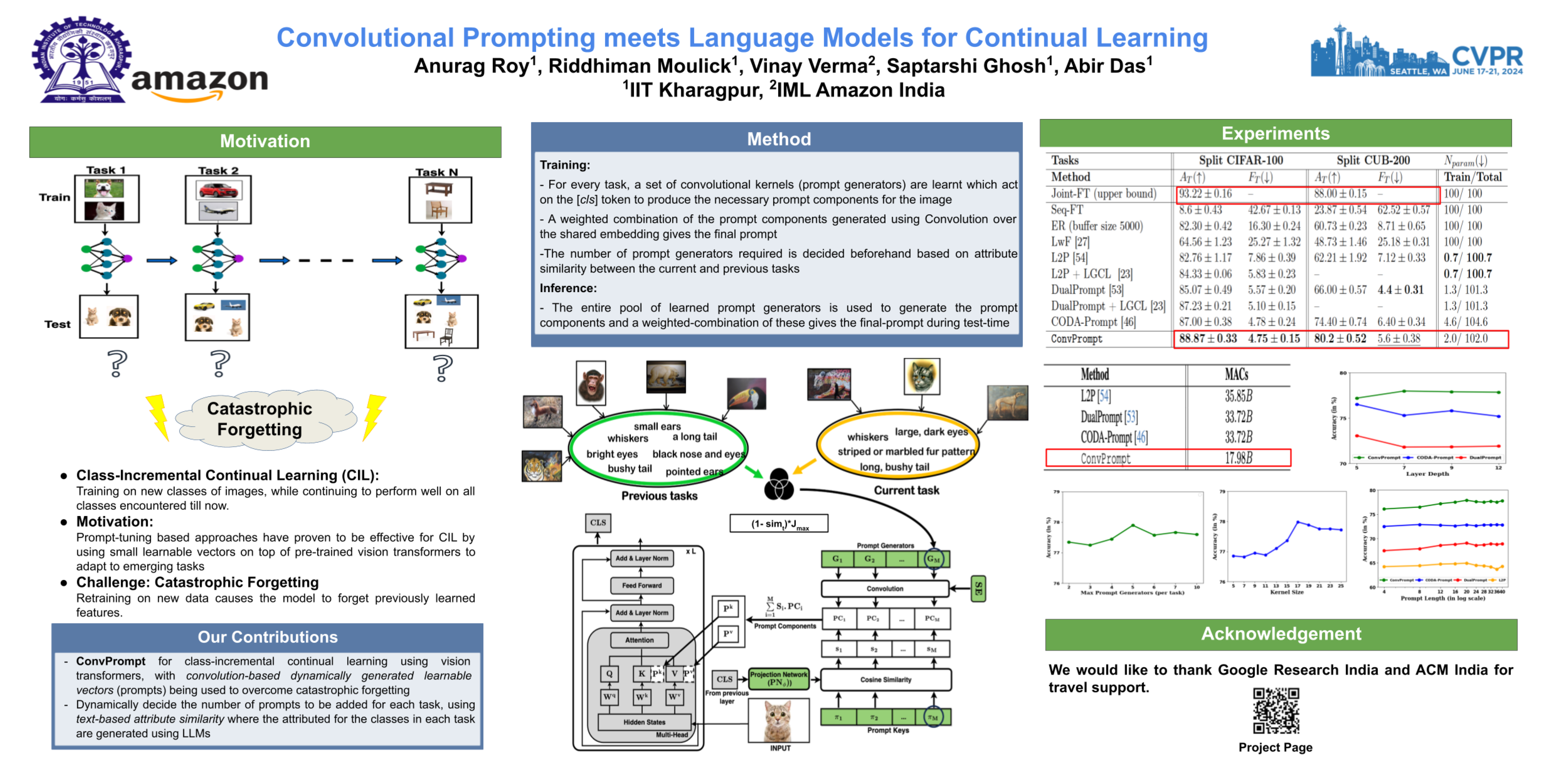
Continual Learning (CL) enables machine learning models to learn from continuously shifting new training data in absence of data from old tasks. Recently, pre-trained vision transformers combined with prompt tuning have shown promise for overcoming catastrophic forgetting in CL. These approaches rely on a pool of learnable prompts which can be inefficient in sharing knowledge across tasks leading to inferior performance. In addition, the lack of fine-grained layer specific prompts does not allow these to fully express the strength of the prompts for CL. We address these limitations by proposing ConvPrompt, a novel convolutional prompt creation mechanism that maintains layer-wise shared embeddings, enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. Extensive experiments demonstrate the superiority of ConvPrompt and improves SOTA by $\sim 3$% with significantly less parameter overhead. We also perform strong ablation over various modules to disentangle the importance of different components. Our code will be made public.
Chat is not available.
Successful Page Load