MemoNav: Working Memory Model for Visual Navigation
 Highlight
Highlight
{kind=link}
Abstract
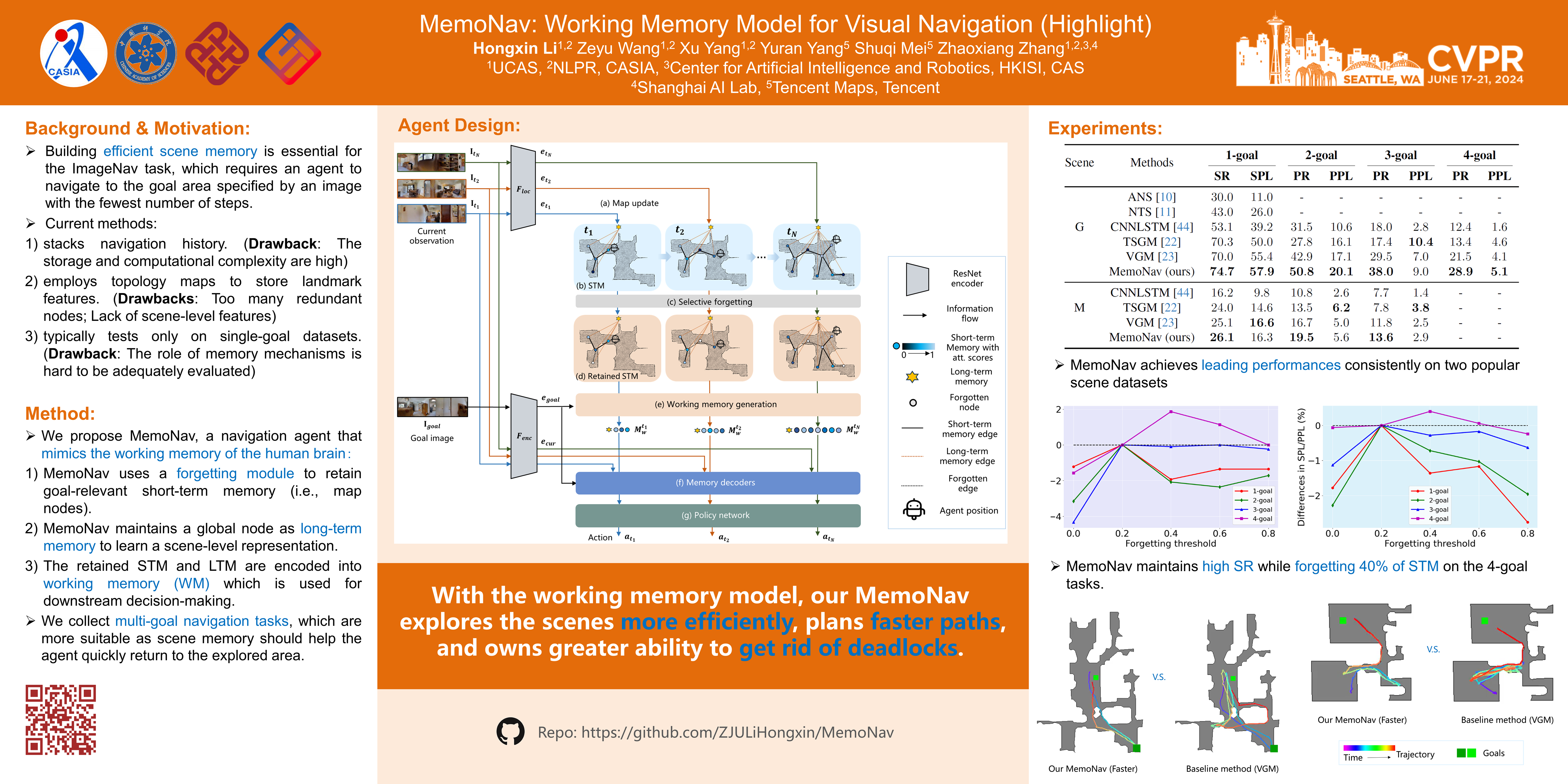
Image-goal navigation is a challenging task that requires an agent to navigate to a goal indicated by an image in unfamiliar environments. Existing methods utilizing diverse scene memories suffer from inefficient exploration since they use all historical observations for decision-making without considering the goal-relevant fraction. To address this limitation, we present MemoNav, a novel memory model for image-goal navigation, which utilizes a working memory-inspired pipeline to improve navigation performance. Specifically, we employ three types of navigation memory. The node features on a map are stored in the short-term memory (STM), as these features are dynamically updated. A forgetting module then retains the informative STM fraction to increase efficiency. We also introduce long-term memory (LTM) to learn global scene representations by progressively aggregating STM features. Subsequently, a graph attention module encodes the retained STM and the LTM to generate working memory (WM) which contains the scene features essential for efficient navigation. The synergy among these three memory types boosts navigation performance by enabling the agent to learn and leverage goal-relevant scene features within a topological map. Our evaluation on multi-goal tasks demonstrates that MemoNav significantly outperforms previous methods across all difficulty levels in both Gibson and Matterport3D scenes. Qualitative results further illustrate that MemoNav plans more efficient routes.