Vector Graphics Generation via Mutually Impulsed Dual-domain Diffusion
{kind=link}
Abstract
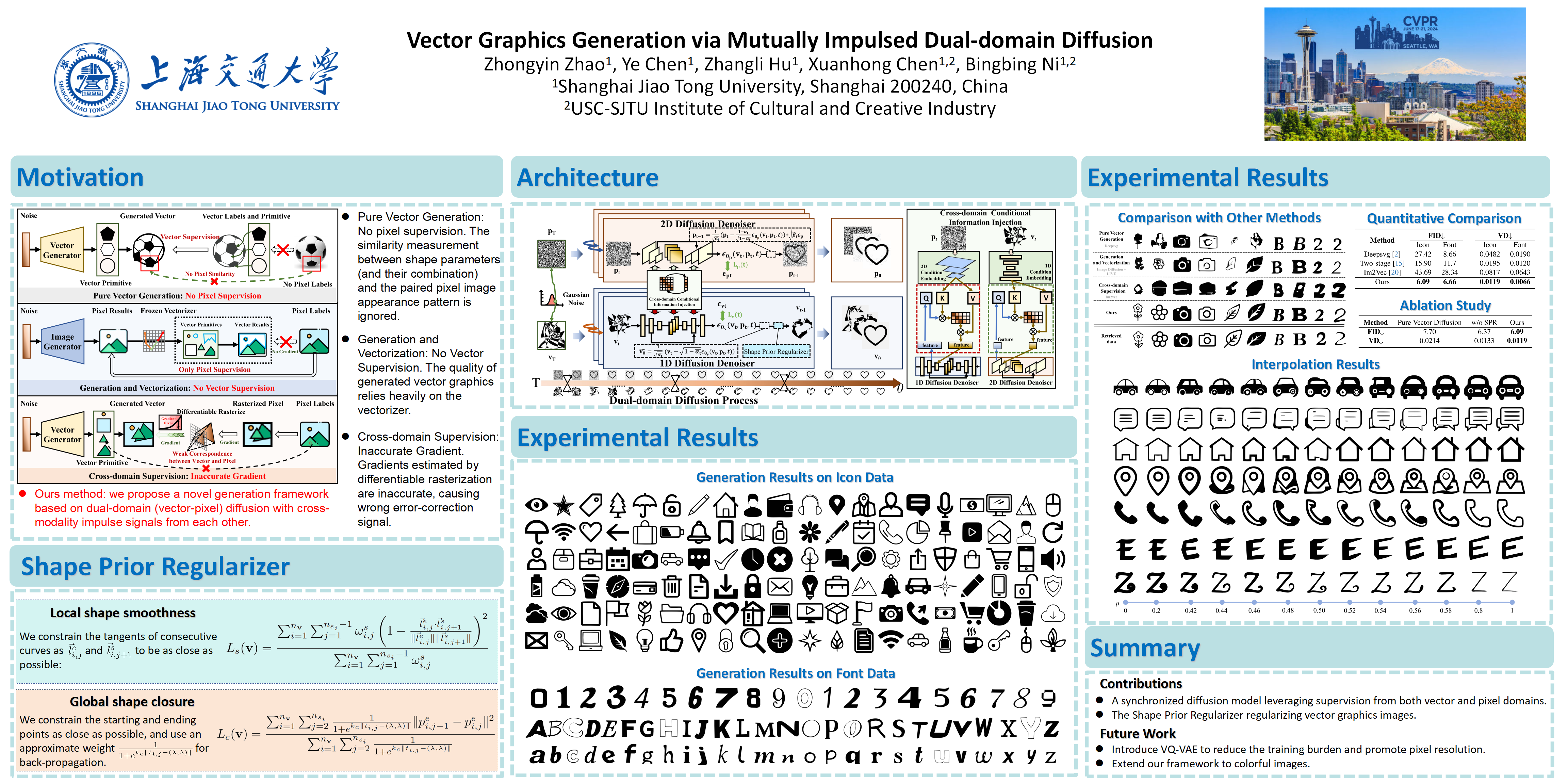
Intelligent generation of vector graphics has very promising applications in the fields of advertising and logo design, artistic painting, animation production, etc. However, current mainstream vector image generation methods based on diffusion models lack the encoding of image appearance information that is associated with the original vector representation and therefore lose valid supervision signal from the strong correlation between the discrete vector parameter (drawing instruction) sequence and the target shape/structure of the corresponding pixel image. On the one hand, the generation process based on pure vector domain completely ignores the similarity measurement between shape parameter (and their combination) and the paired pixel image appearance pattern; on the other hand, two-stage methods (i.e., generation-and-vectorization) based on pixel diffusion followed by differentiable image-to-vector translation suffer from wrong error-correction signal caused by approximate gradients. To address the above issues, we propose a novel generation framework based on dual-domain (vector-pixel) diffusion with cross-modality impulse signals from each other. First, in each diffusion step, the current representation extracted from the other domain is used as a condition variable to constrain the subsequent sampling operation, yielding shape-aware new parameterizations; second, independent supervision signals from both domains avoid the gradient error accumulation problem caused by cross-domain representation conversion. Extensive experimental results on popular benchmarks including font and icon datasets demonstrate the great advantages of our proposed framework in terms of generated shape quality.