Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning
{kind=link}
Abstract
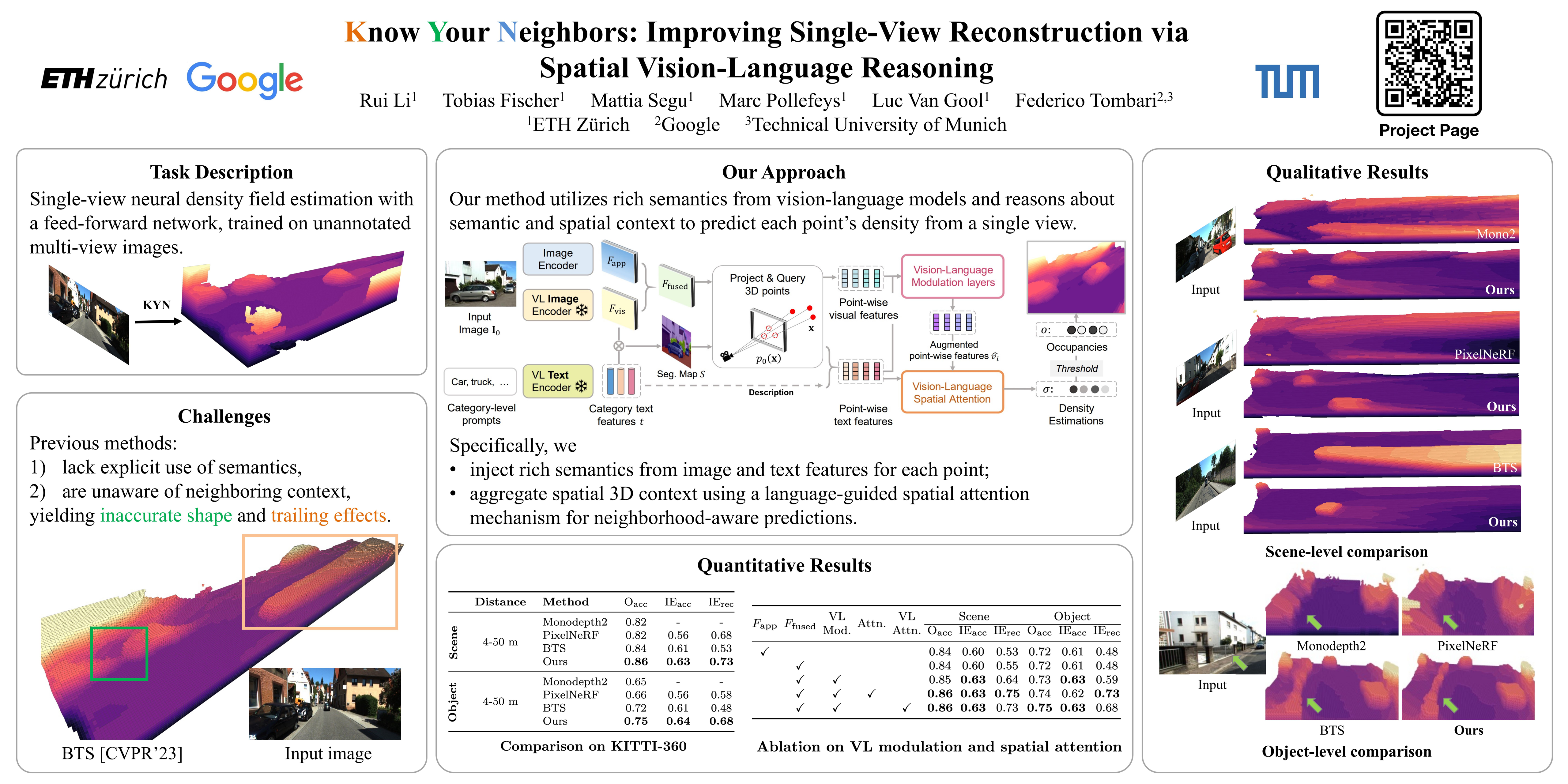
Recovering the 3D scene geometry from a single view is a fundamental yet ill-posed problem in computer vision. While classical depth estimation methods infer only a 2.5D scene representation limited to the image plane, recent approaches based on radiance fields reconstruct a full 3D representation. However, these methods still struggle with occluded regions since inferring geometry without visual observation requires (i) semantic knowledge of the surroundings, and (ii) reasoning about spatial context. We propose KYN, a novel method for single-view scene reconstruction that reasons about semantic and spatial context to predict each point's density. We introduce a vision-language modulation module to enrich point features with fine-grained semantic information. We aggregate point representations across the scene through a language-guided spatial attention mechanism to yield per-point density predictions aware of the 3D semantic context. We show that KYN improves 3D shape recovery compared to predicting density for each 3D point in isolation. We achieve state-of-the-art results in scene and object reconstruction on KITTI-360, and show improved zero-shot generalization compared to prior work. Project page: https://ruili3.github.io/kyn.