FACT: Frame-Action Cross-Attention Temporal Modeling for Efficient Action Segmentation
{kind=link}
Abstract
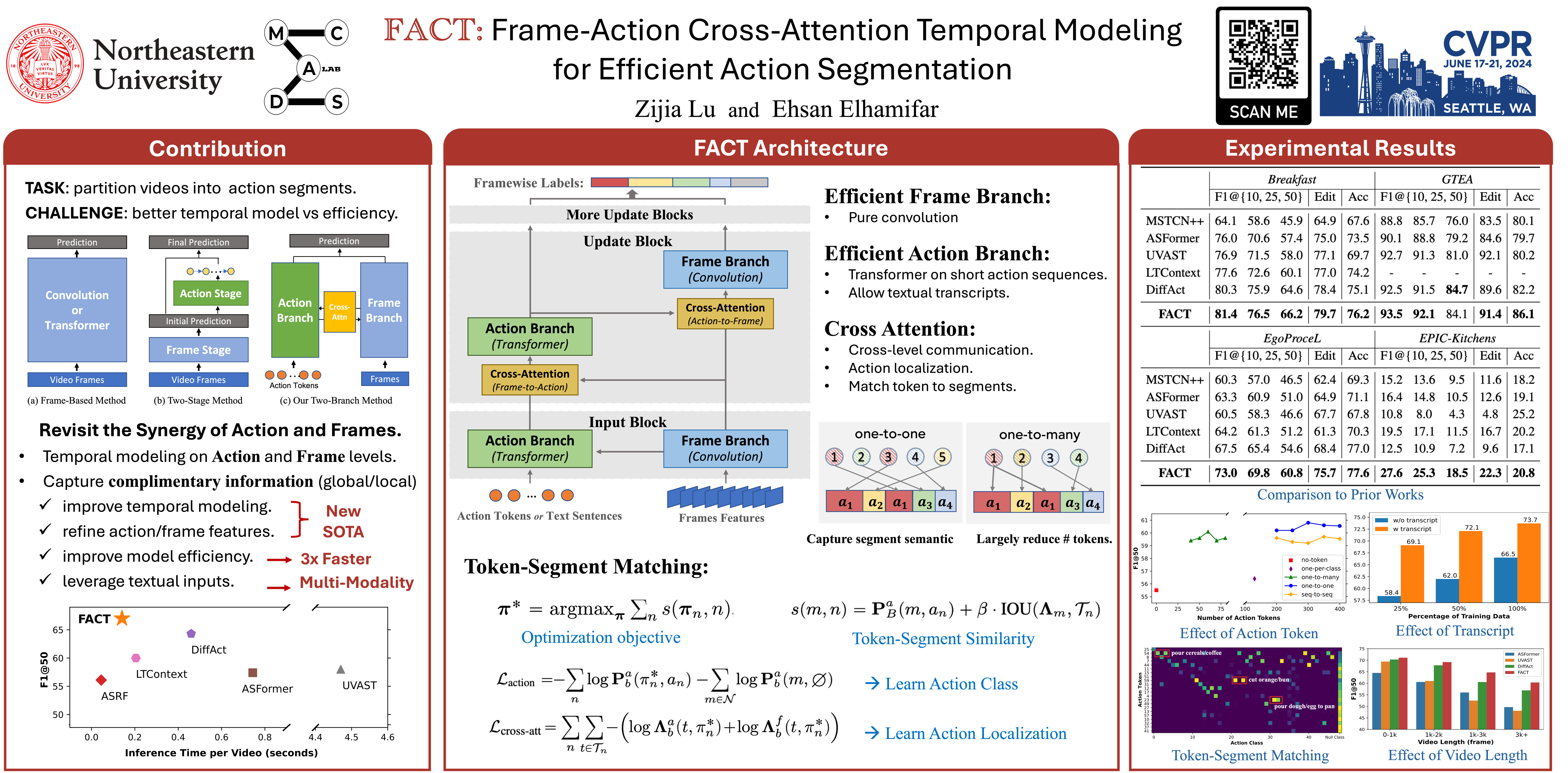
We study supervised action segmentation, whose goal is to predict framewise action labels of a video. To capture temporal dependencies over long horizons, prior works either improve framewise features with transformer or refine framewise predictions with learned action features. However, they ignore that frame and action features contain complimentary information, which can be leveraged to enhance both features and improve temporal modeling. Therefore, we propose an efficient Frame-Action Cross-attention Temporal modeling (FACT) framework that performs temporal modeling with frame and action features in parallel and leverage this parallelism to achieve iterative bidirectional information transfer between the features and refine them. FACT network contains (i) a frame branch to learn frame-level information with convolutions and frame features, (ii) an action branch to learn action-level dependencies with transformers and action tokens and (iii) cross-attentions to allow communication between the two branches. We also propose a new matching loss to ensure each action token uniquely encodes an action segment, thus better captures its semantics. Thanks to our architecture, we can also leverage textual transcripts of videos to help action segmentation. We evaluate FACT on four video datasets (two egocentric and two third-person) for action segmentation with and without transcripts, showing that FACT significantly improves the state-of-the-art accuracy while enjoys lower computational cost (3 times faster) than existing transformer-based methods.