FlowVQTalker: High-Quality Emotional Talking Face Generation through Normalizing Flow and Quantization
{kind=link}
Abstract
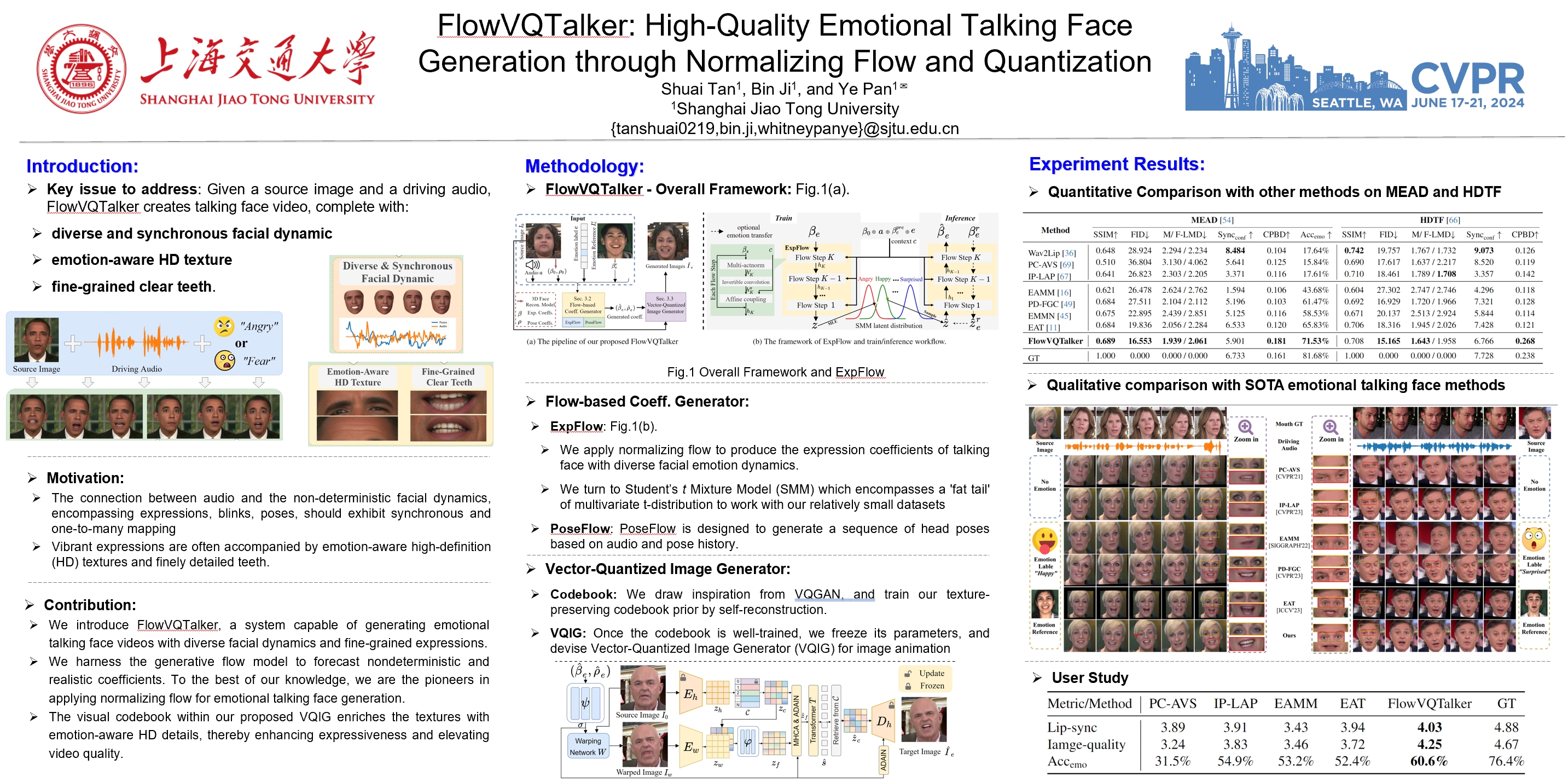
Generating emotional talking faces is a practical yet challenging endeavor. To create a lifelike avatar, we draw upon two critical insights from a human perspective: 1) The connection between audio and the non-deterministic facial dynamics, encompassing expressions, blinks, poses, should exhibit synchronous and one-to-many mapping. 2) Vibrant expressions are often accompanied by emotion-aware high-definition (HD) textures and finely detailed teeth. However, both aspects are frequently overlooked by existing methods. To this end, this paper proposes using normalizing Flow and Vector-Quantization modeling to produce emotional talking faces that satisfy both insights concurrently (FlowVQTalker). Specifically, we develop a flow-based coefficient generator that encodes the dynamics of facial emotion into a multi-emotion-class latent space represented as a mixture distribution. The generation process commences with random sampling from the modeled distribution, guided by the accompanying audio, enabling both lip-synchronization and the uncertain nonverbal facial cues generation. Furthermore, our designed vector-quantization image generator treats the creation of expressive facial images as a code query task, utilizing a learned codebook to provide rich, high-quality textures that enhance the emotional perception of the results. Extensive experiments are conducted to showcase the effectiveness of our approach.