Leveraging Cross-Modal Neighbor Representation for Improved CLIP Classification
{kind=link}
Abstract
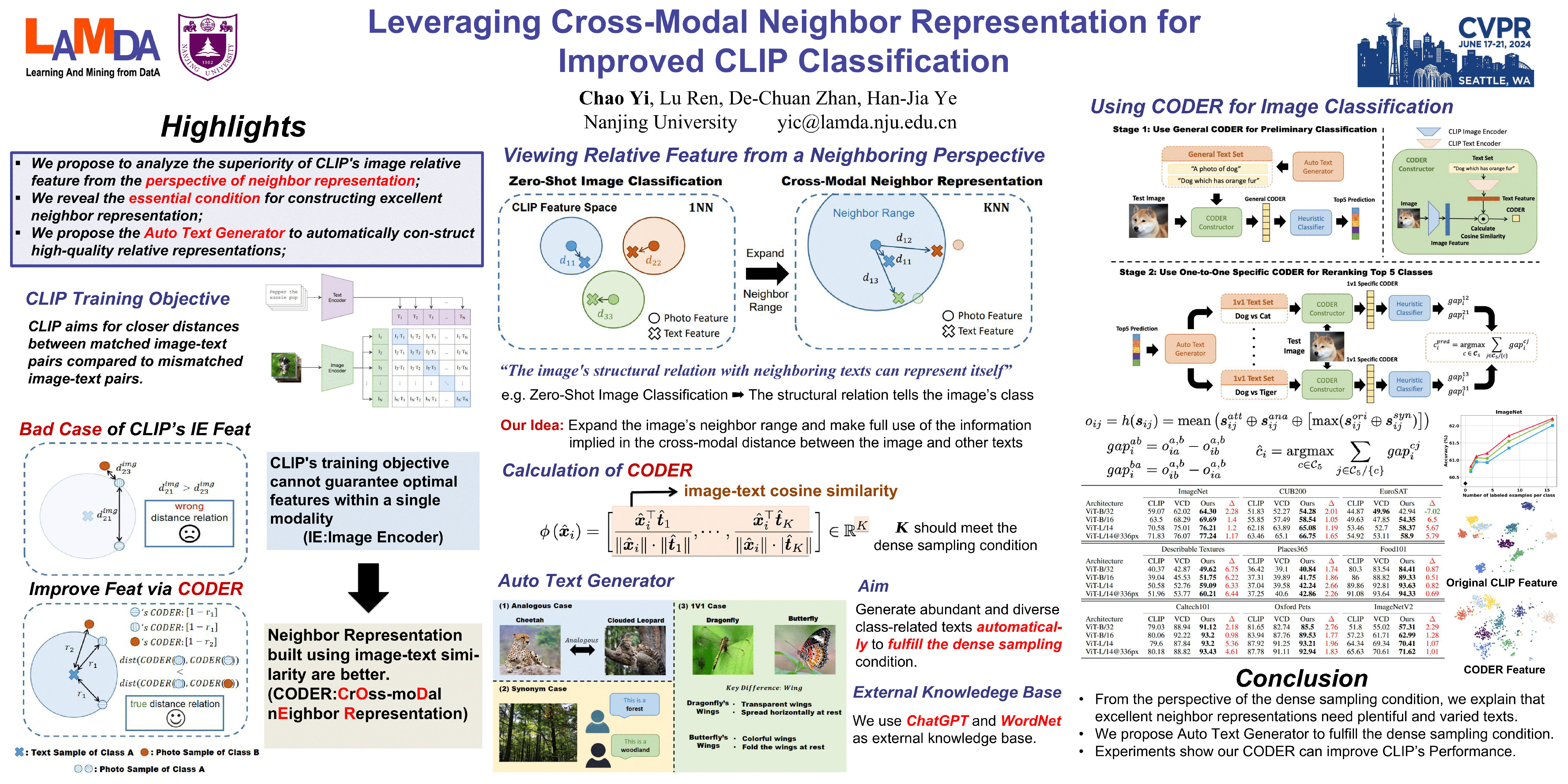
CLIP showcases exceptional cross-modal matching capabilities due to its training on image-text contrastive learning tasks. However, without specific optimization for unimodal scenarios, its performance in single-modality feature extraction might be suboptimal. Despite this, some studies have directly used CLIP’s image encoder for tasks like few-shot classification, introducing a misalignment between itspre-training objectives and feature extraction methods. This inconsistency can diminish the quality of the image's feature representation, adversely affecting CLIP’s effectiveness in target tasks. In this paper, we view text features as precise neighbors of image features in CLIP’s space and present a novel CrOss-moDal nEighbor Representation (CODER) based on the distance structure between images and their neighbor texts. This feature extraction method aligns better with CLIP’s pre-training objectives, thereby fully leveraging CLIP’s robust cross-modal capabilities. The key to construct a high-quality CODER lies in how to create a vast amount of high-quality and diverse texts to match with images. We introduce the Auto Text Generator (ATG) to automatically produce the required text in a data-free and training-free manner. We apply CODER to CLIP’s zero-shot and few-shot image classification tasks. Experiment results across various datasets and models confirm CODER’s effectiveness. Code is available at: https://github.com/YCaigogogo/CVPR24-CODER.