MPOD123: One Image to 3D Content Generation Using Mask-enhanced Progressive Outline-to-Detail Optimization
{kind=link}
Abstract
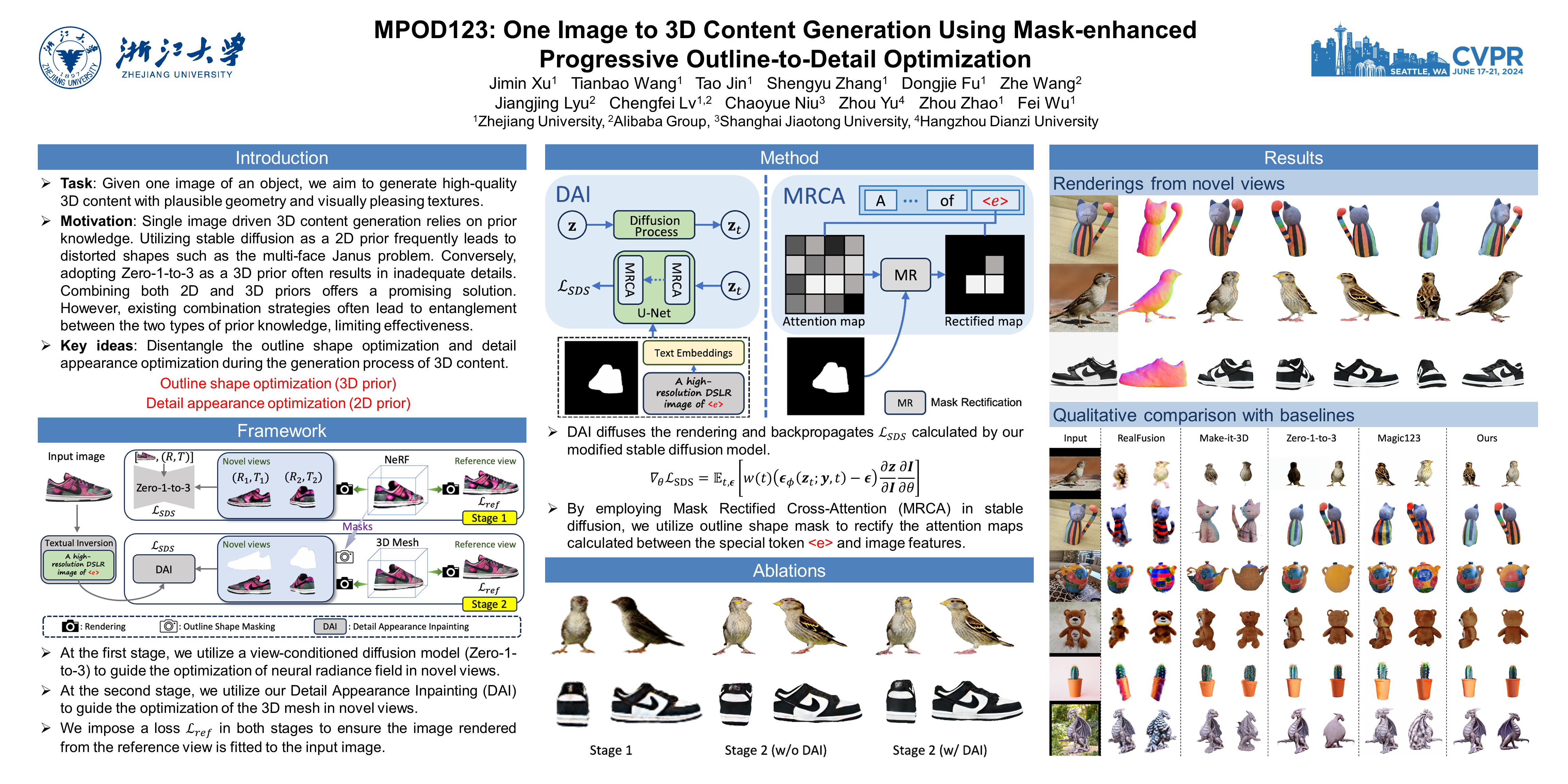
Recent advancements in single image driven 3D content generation have been propelled by leveraging prior knowledge from pretrained 2D diffusion models. However, the 3D content generated by existing methods often exhibits distorted outline shapes and inadequate details. To solve this problem, we propose a novel framework called Mask-enhanced Progressive Outline-to-Detail optimization (aka. MPOD123), which consists of two stages. Specifically, in the first stage, MPOD123 utilizes the pretrained view-conditioned diffusion model to guide the outline shape optimization of the 3D content. Given certain viewpoint, we estimate outline shape priors in the form of 2D mask from the 3D content by leveraging opacity calculation. In the second stage, MPOD123 incorporates Detail Appearance Inpainting (DAI) to guide the refinement on local geometry and texture with the shape priors. The essence of DAI lies in the Mask Rectified Cross-Attention (MRCA), which can be conveniently plugged in the stable diffusion model. The MRCA module utilizes the mask to rectify the attention map from each cross-attention layer. Accompanied with this new module, DAI is capable of guiding the detail refinement of the 3D content, while better preserves the outline shape. To assess the applicability in practical scenarios, we contribute a new dataset modeled on real-world e-commerce environments. Extensive quantitative and qualitative experiments on this dataset and open benchmarks demonstrate the effectiveness of MPOD123 over the state-of-the-arts.