Data-Free Quantization via Pseudo-label Filtering
{kind=link}
Abstract
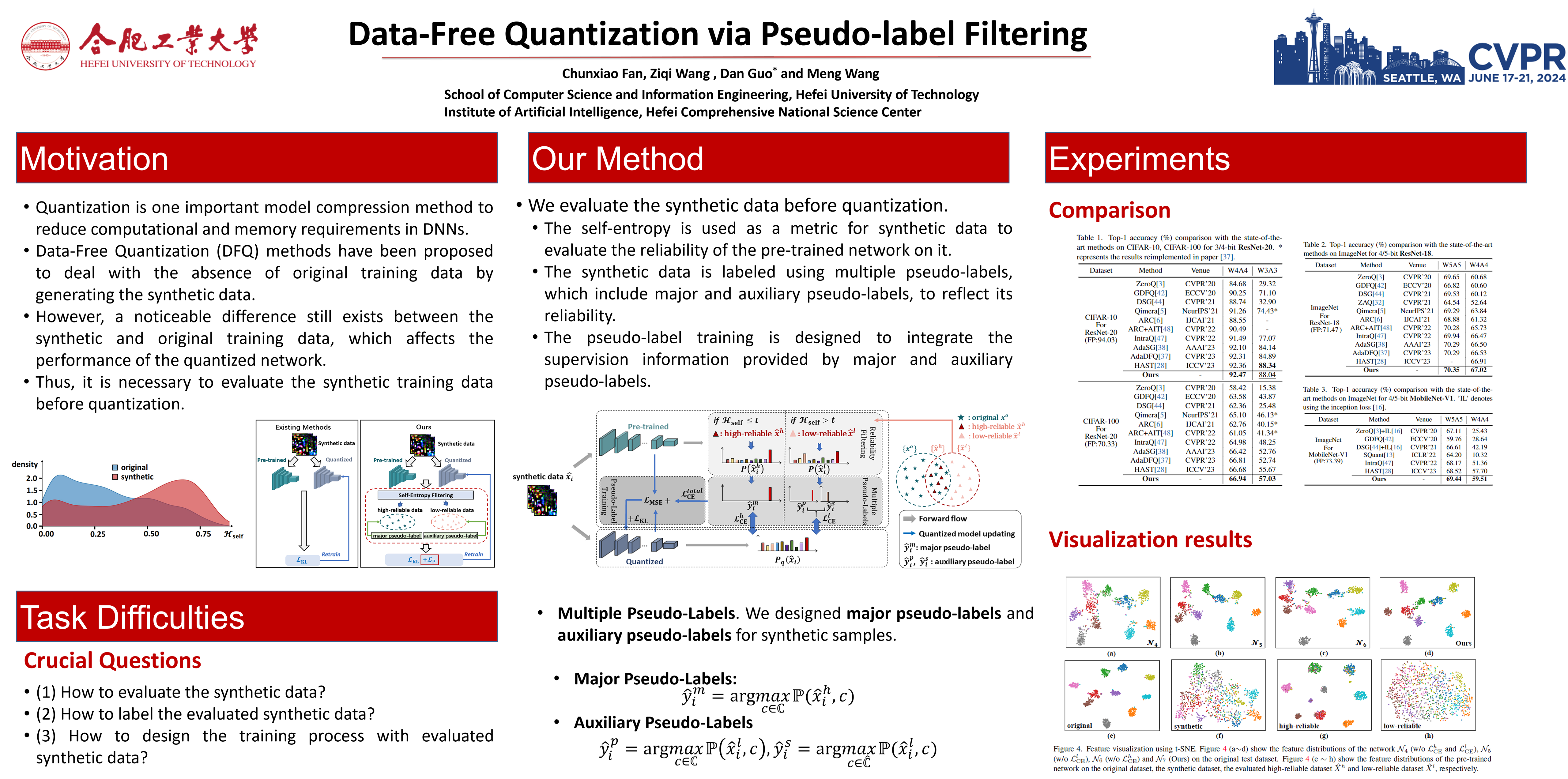
Quantization for model compression can efficiently reduce the network complexity and storage requirement, but the original training data is necessary to remedy the performance loss caused by quantization. The Data-Free Quantization (DFQ) methods have been proposed to handle the absence of original training data with synthetic data. However, there are differences between the synthetic and original training data, which affects the performance of the quantized network, but none of the existing methods considers the differences. In this paper, we propose an efficient data-free quantization via pseudo-label filtering, which is the first to evaluate the synthetic data before quantization. We design a new metric for evaluating synthetic data using self-entropy, which indicates the reliability of synthetic data. The synthetic data can be categorized with the metric into high- and low-reliable datasets for the following training process. Besides, the multiple pseudo-labels are designed to label the synthetic data with different reliability, which can provide valuable supervision information and avoid misleading training by low-reliable samples. Extensive experiments are implemented on several datasets, including CIFAR-10, CIFAR-100, and ImageNet with various models. The experimental results show that our method can perform excellently and outperform existing methods in accuracy.