Skeleton-in-Context: Unified Skeleton Sequence Modeling with In-Context Learning
{kind=link}
Abstract
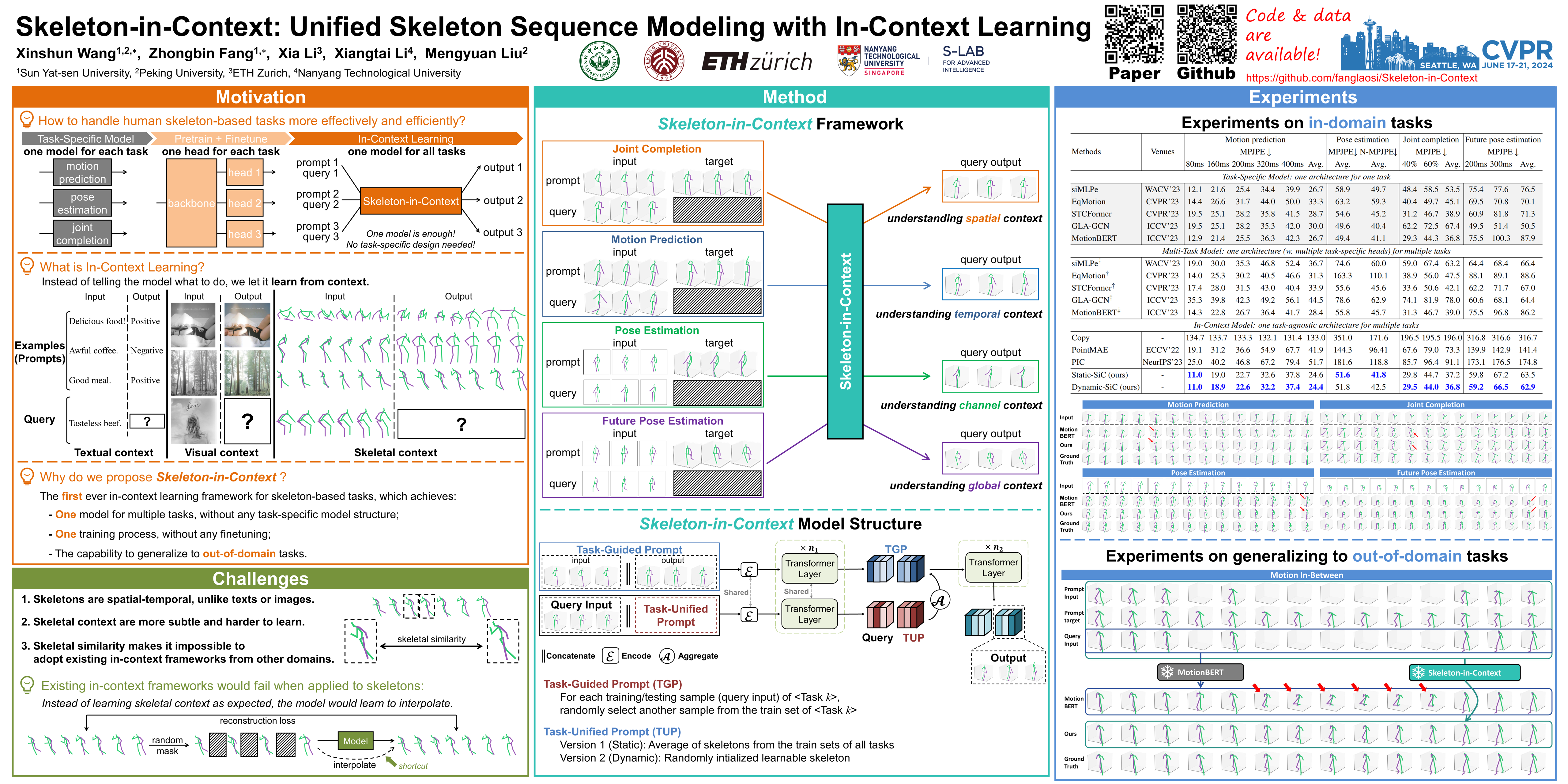
In-context learning provides a new perspective for multi-task modeling for vision and NLP. Under this setting, the model can perceive tasks from prompts and accomplish them without any extra task-specific head predictions or model finetuning. However, Skeleton sequence modeling via in-context learning remains unexplored. Directly applying existing in-context models from other areas onto skeleton sequences fails due to the inter-frame and cross-task pose similarity that makes it outstandingly hard to perceive the task correctly from a subtle context. To address this challenge, we propose Skeleton-in-Context (SiC), an effective framework for in-context skeleton sequence modeling. Our SiC is able to handle multiple skeleton-based tasks simultaneously after a single training process and accomplish each task from context according to the given prompt. It can further generalize to new, unseen tasks according to customized prompts. To facilitate context perception, we additionally propose a task-unified prompt, which adaptively learns tasks of different natures, such as partial joint-level generation, sequence-level prediction, or 2D-to-3D motion prediction. We conduct extensive experiments to evaluate the effectiveness of our SiC on multiple tasks, including motion prediction, pose estimation, joint completion, and future pose estimation. We also evaluate its generalization capability on unseen tasks such as motion-in-between. These experiments show that our model achieves state-of-the-art multi-task performance and even outperforms single-task methods on certain tasks.