Benchmarking Audio Visual Segmentation for Long-Untrimmed Videos
Chen Liu ⋅ Peike Li ⋅ Qingtao Yu ⋅ Hongwei Sheng ⋅ Dadong Wang ⋅ Lincheng Li ⋅ Xin Yu
2024 Poster
{kind=link}
Abstract
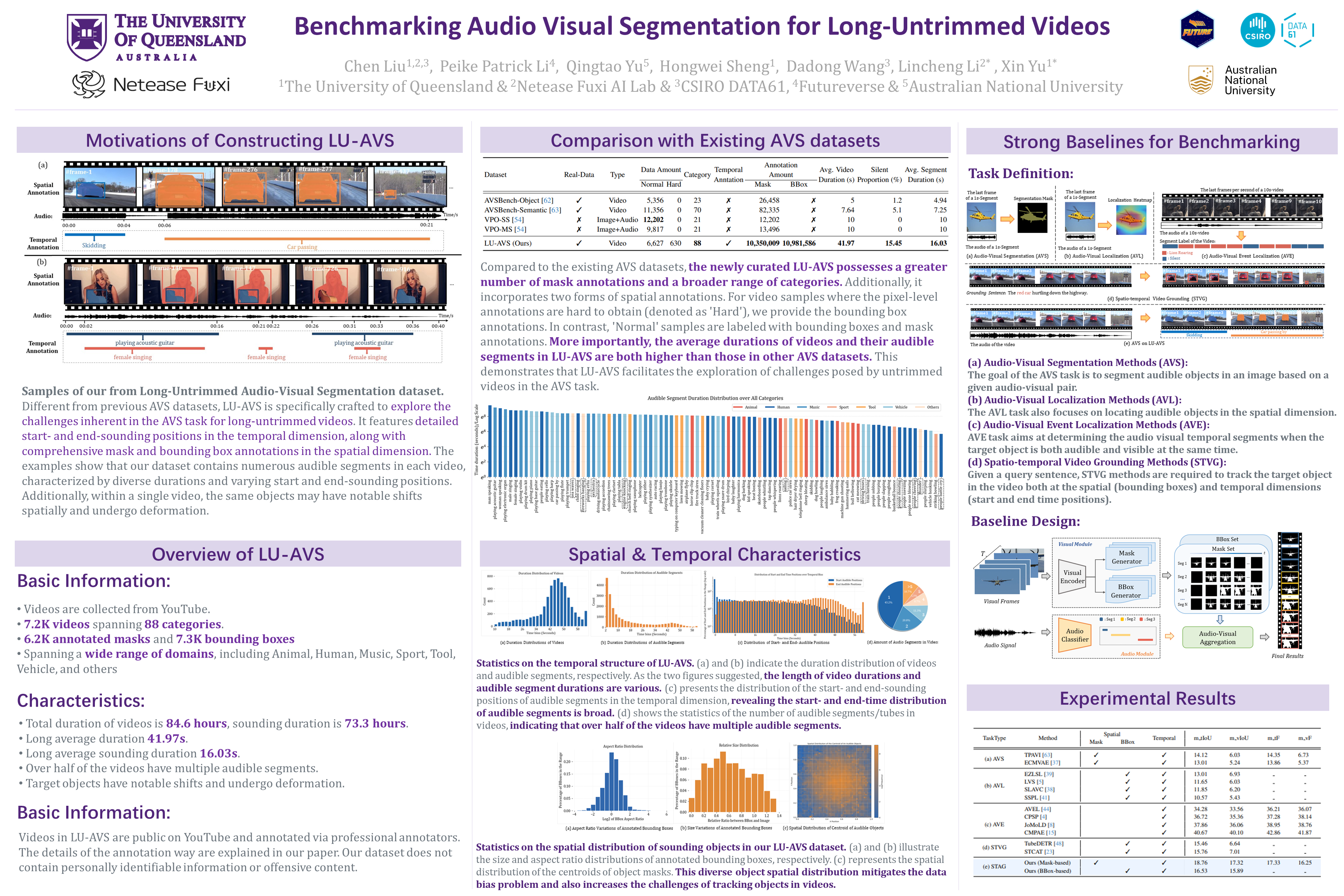
Existing audio-visual segmentation (AVS) datasets typically focus on short-trimmed videos with only one pixel-map annotation for a per-second video clip. In contrast, for untrimmed videos, the sound duration, start- and end-sounding time positions, and visual deformation of audible objects vary significantly. Therefore, we observed that current AVS models trained on trimmed videos might struggle to segment sounding objects in long videos. To investigate the feasibility of grounding audible objects in videos along both temporal and spatial dimensions, we introduce the Long-Untrimmed Audio-Visual Segmentation dataset (LU-AVS), which includes precise frame-level annotations of sounding emission times and provides exhaustive mask annotations for all frames. Considering that pixel-level annotations are difficult to achieve in some complex scenes, we also provide the bounding boxes to indicate the sounding regions. Specifically, LU-AVS contains 62K mask annotations across 6K videos, and 73K bounding box annotations across 7K videos. Compared with the existing datasets, LU-AVS videos are on average 4$\sim$8 times longer, with the silent duration being 2$\sim$10 times greater. Furthermore, we try our best to adapt some baseline models that were originally designed for audio-visual-relevant tasks to examine the challenges of our newly curated LU-AVS dataset. Through comprehensive evaluation, we demonstrate the challenges of the LU-AVS datasets compared to the ones containing trimmed videos. Therefore, LU-AVS provides an ideal yet challenging platform for evaluating audio-visual segmentation and localization on untrimmed long videos.
Chat is not available.
Successful Page Load