Unsupervised Learning of Category-Level 3D Pose from Object-Centric Videos
{kind=link}
Abstract
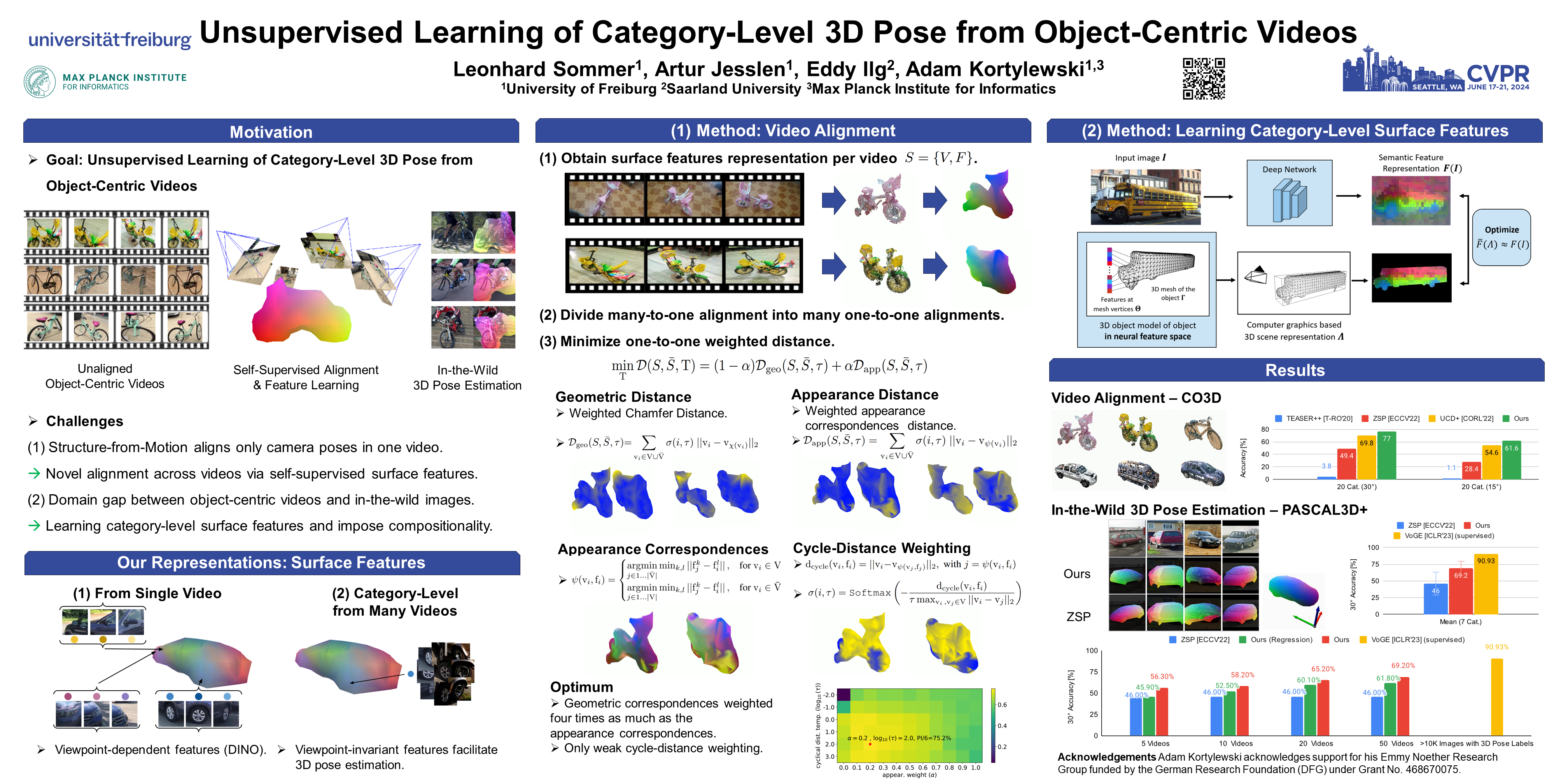
Category-level 3D pose estimation is a fundamentally important problem in computer vision and robotics, e.g. for embodied agents or to train 3D generative models. However, so far methods that estimate the category-level object pose require either large amounts of human annotations, CAD models or input from RGB-D sensors. In contrast, we tackle the problem of learning to estimate the category-level 3D pose only from casually taken object-centric videos without human supervision. We propose a two-step pipeline: First, we introduce a multi-view alignment procedure that determines canonical camera poses across videos with a novel and robust cyclic distance formulation for geometric and appearance matching using reconstructed coarse meshes and DINOv2 features. In a second step, the canonical poses and reconstructed meshes enable us to train a model for 3D pose estimation from a single image. In particular, our model learns to estimate dense correspondences between images and a prototypical 3D template by predicting, for each pixel in a 2D image, a feature vector of the corresponding vertex in the template mesh. We demonstrate that our method outperforms all baselines at the unsupervised alignment of object-centric videos by a large margin and provides faithful and robust predictions in-the-wild on the Pascal3D+ and ObjectNet3D datasets.