SCE-MAE: Selective Correspondence Enhancement with Masked Autoencoder for Self-Supervised Landmark Estimation
Kejia Yin ⋅ Varshanth Rao ⋅ Ruowei Jiang ⋅ Xudong Liu ⋅ Parham Aarabi ⋅ David B. Lindell
2024 Poster
{kind=link}
Abstract
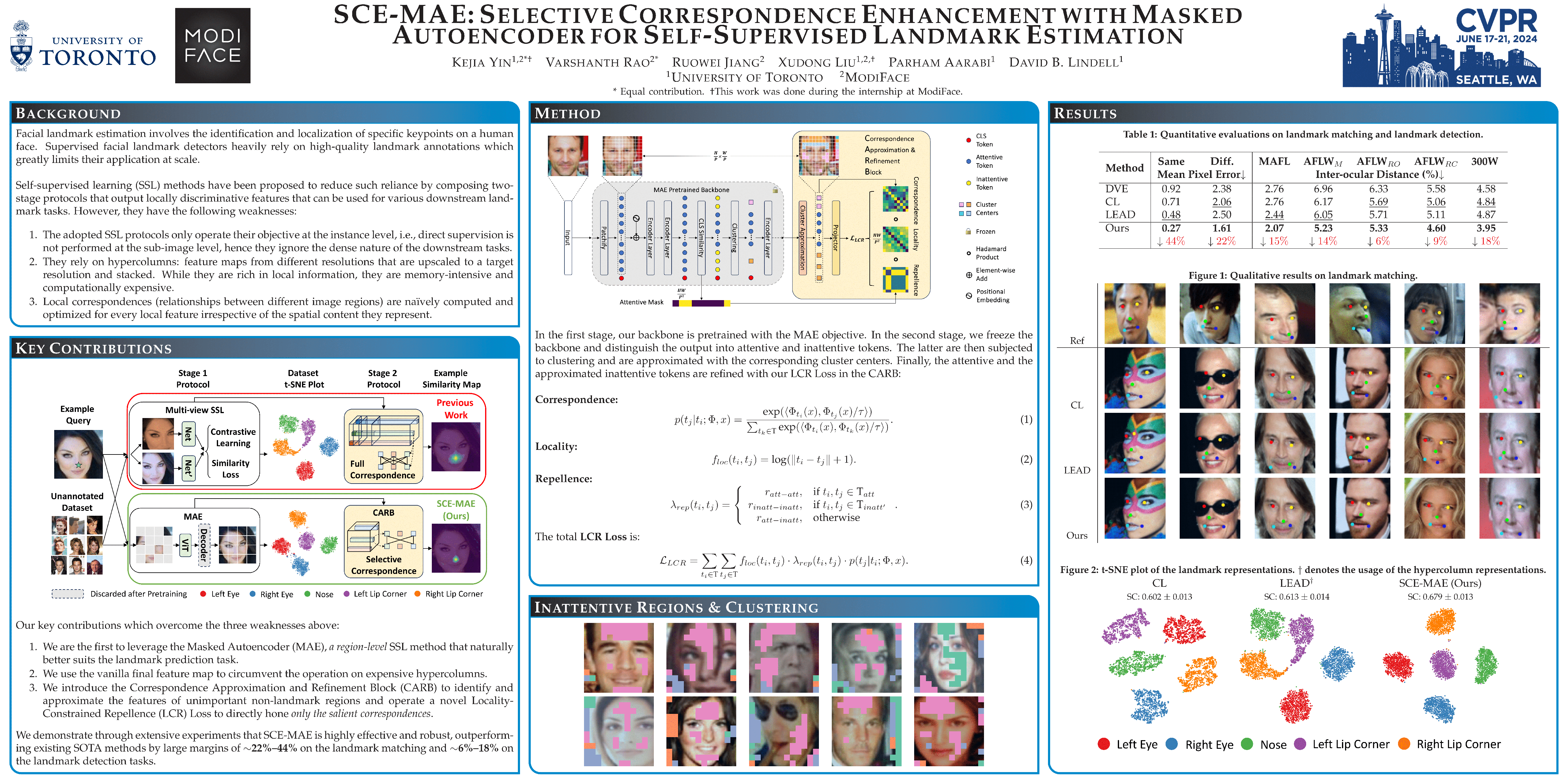
Self-supervised landmark estimation is a challenging task that demands the formation of locally distinct feature representations to identify sparse facial landmarks in the absence of annotated data. To tackle this task, existing state-of-the-art (SOTA) methods (1) extract coarse features from backbones that are trained with instance-level self-supervised learning (SSL) paradigms, which neglect the dense prediction nature of the task, (2) aggregate them into memory-intensive hypercolumn formations, and (3) supervise lightweight projector networks to naively establish full local correspondences among all pairs of spatial features. In this paper, we introduce SCE-MAE, a framework that (1) leverages the MAE, a region-level SSL method that naturally better suits the landmark prediction task, (2) operates on the vanilla feature map instead of on expensive hypercolumns, and (3) employs a Correspondence Approximation and Refinement Block (CARB) that utilizes a simple density peak clustering algorithm and our proposed Locality-Constrained Repellence Loss to directly hone only select local correspondences. We demonstrate through extensive experiments that SCE-MAE is highly effective and robust, outperforming existing SOTA methods by large margins of $\sim$20\%-44\% on the landmark matching and $\sim$9\%-15\% on the landmark detection tasks.
Chat is not available.
Successful Page Load