DMR: Decomposed Multi-Modality Representations for Frames and Events Fusion in Visual Reinforcement Learning
{kind=link}
Abstract
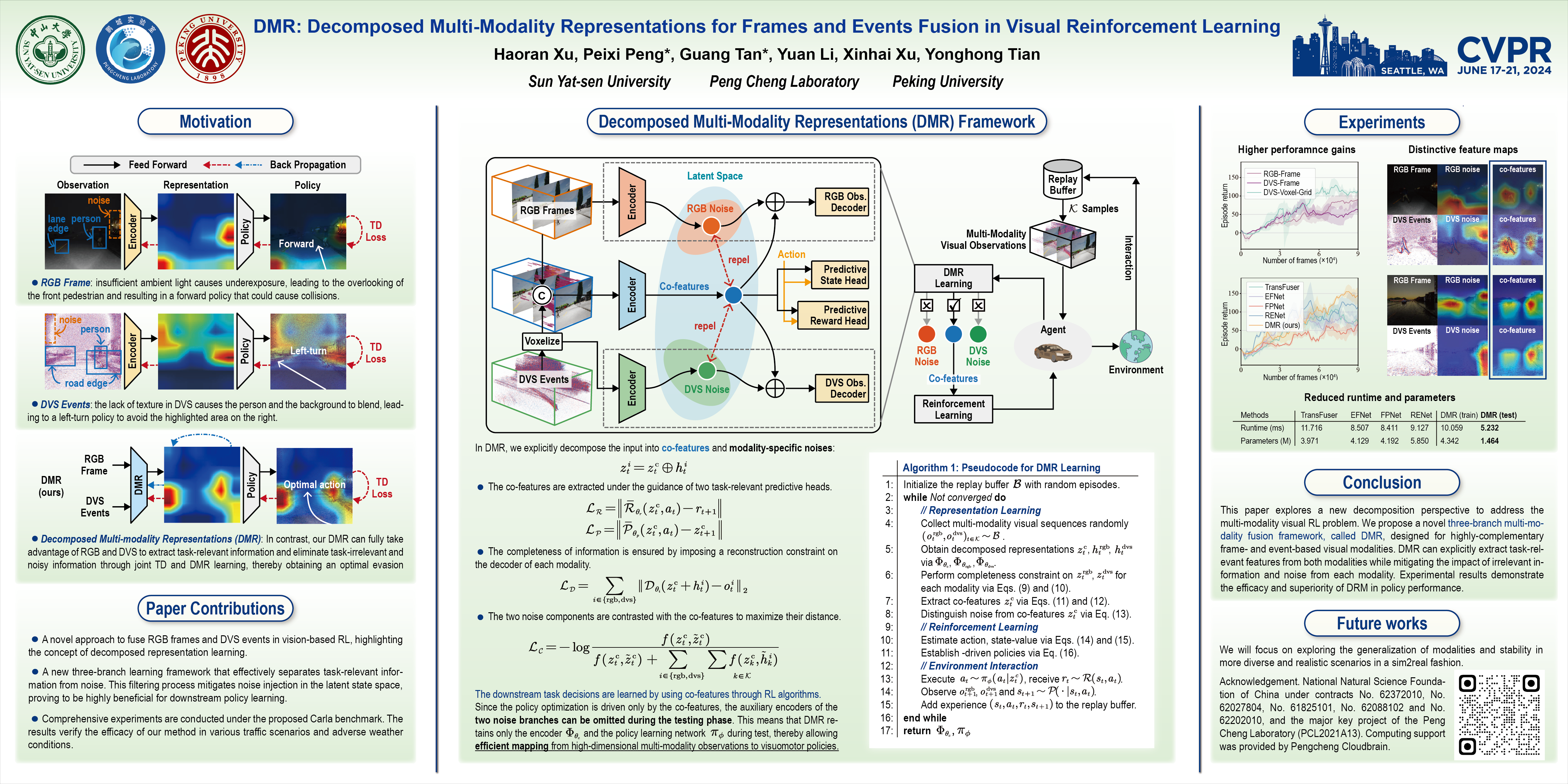
We explore visual reinforcement learning (RL) using two complementary visual modalities: frame-based RGB camera and event-based Dynamic Vision Sensor (DVS). Existing multi-modality visual RL methods often encounter challenges in effectively extracting task-relevant information from multiple modalities while suppressing the increased noise, only using indirect reward signals instead of pixel-level supervision. To tackle this, we propose a Decomposed Multi-Modality Representation (DMR) framework for visual RL. It explicitly decomposes the inputs into three distinct components: combined task-relevant features (co-features), RGB-specific noise, and DVS-specific noise. The co-features represent the full information from both modalities that is relevant to the RL task; the two noise components, each constrained by a data reconstruction loss to avoid information leak, are contrasted with the co-features to maximize their difference. Extensive experiments demonstrate that, by explicitly separating the different types of information, our approach achieves substantially improved policy performance compared to state-of-the-art approaches.