A Generative Approach for Wikipedia-Scale Visual Entity Recognition
{kind=link}
Abstract
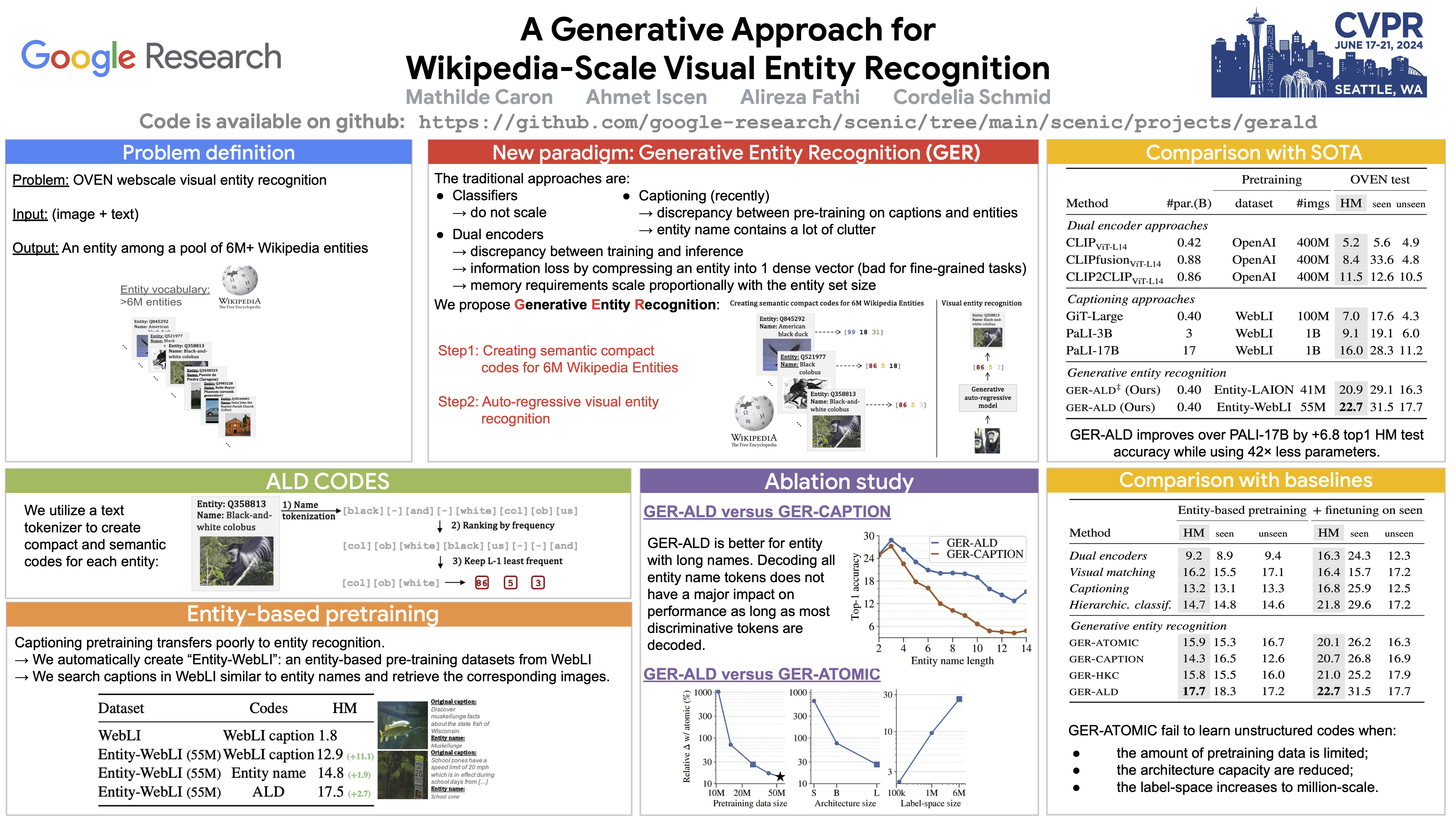
In this paper, we address web-scale visual entity recognition, specifically the task of mapping a given query image to one of the 6 million existing entities in Wikipedia. One way of approaching a problem of such scale is using dual encoder models (e.g. CLIP), where all the entity names and query images are embedded into a unified space, paving the way for an approximate kNN search. Alternatively, it is also possible to re-purpose a captioning model to directly generate the entity names for a given image. In contrast, we introduce a novel Generative Entity Recognition (GER) framework, which given an input image learns to auto-regressively decode a semantic and discriminative “code” identifying the target entity. Our experiments demonstrate the efficacy of this GER paradigm, showcasing state-of-the-art performance on the challenging OVEN benchmark. GER surpasses strong captioning, dual-encoder, visual matching and hierarchical classification baselines, affirming its advantage in tackling the complexities of web-scale recognition.