Seamless Human Motion Composition with Blended Positional Encodings
{kind=link}
Abstract
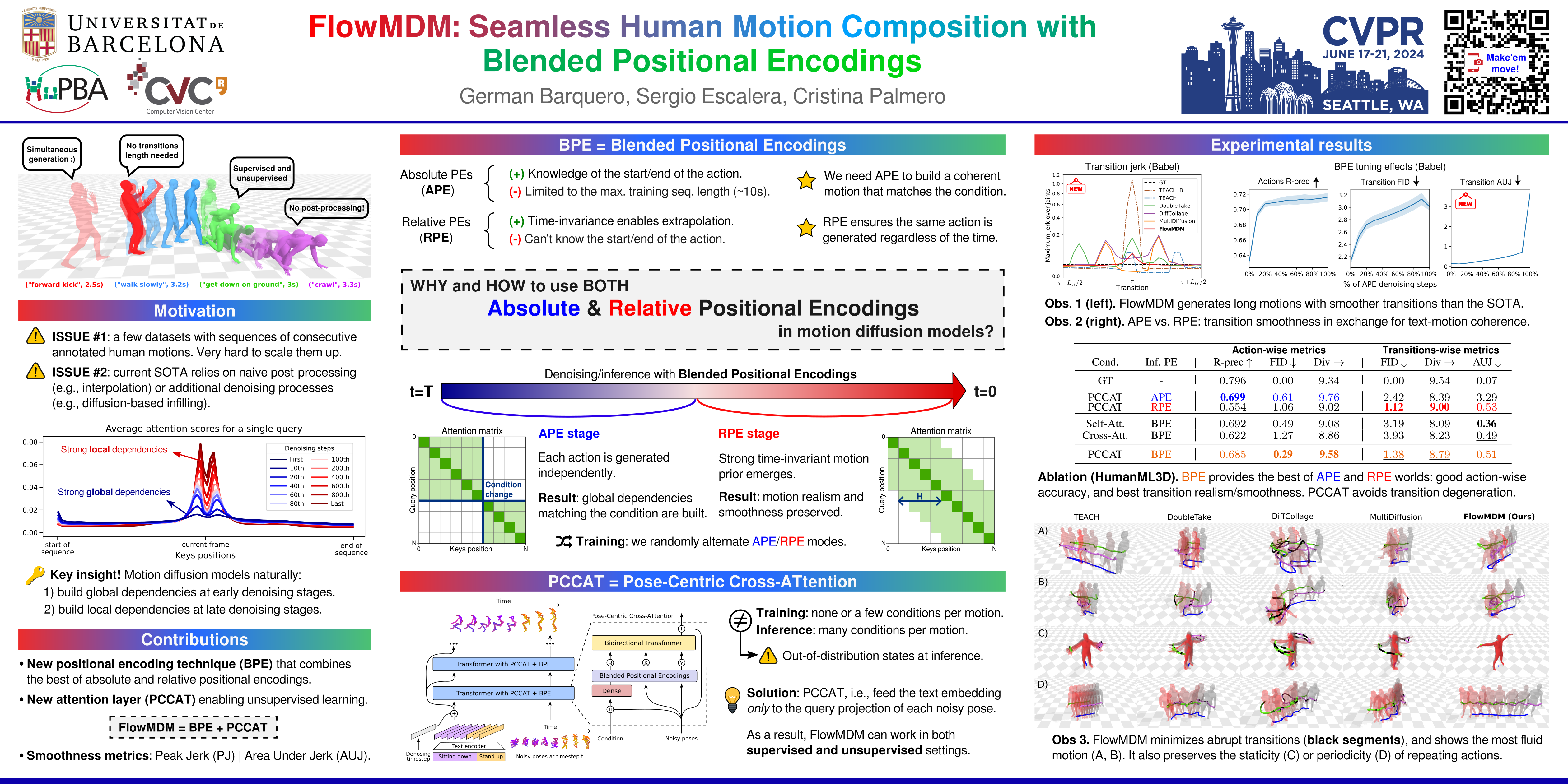
Conditional human motion generation is an important topic with many applications in virtual reality, gaming, and robotics. While prior works have focused on generating motion guided by text, music, or scenes, these typically result in isolated motions confined to short durations. Instead, we address the generation of long, continuous sequences that are guided by a series of varying conditions. In this context, we introduce FlowMDM, the first diffusion-based model that generates seamless Human Motion Compositions (HMC) without any postprocessing or redundant denoising steps. For this, we introduce the Blended Positional Encodings, a technique that leverages both absolute and relative positional encodings in the denoising chain. More specifically, global motion coherence is recovered at the absolute stage, whereas smooth and realistic transitions are built at the relative stage. As a result, we achieve state-of-the-art results in terms of accuracy, realism, and smoothness on the Babel and HumanML3D datasets. FlowMDM excels when trained with only a single condition per motion sequence thanks to its Pose-Centric Cross-ATtention, which makes it robust against varying conditions at inference time. Finally, to address the limitations of existing HMC metrics, we propose two new metrics: the Peak Jerk and the Area Under the Jerk, for detecting abrupt transitions.