Three Pillars Improving Vision Foundation Model Distillation for Lidar
{kind=link}
Abstract
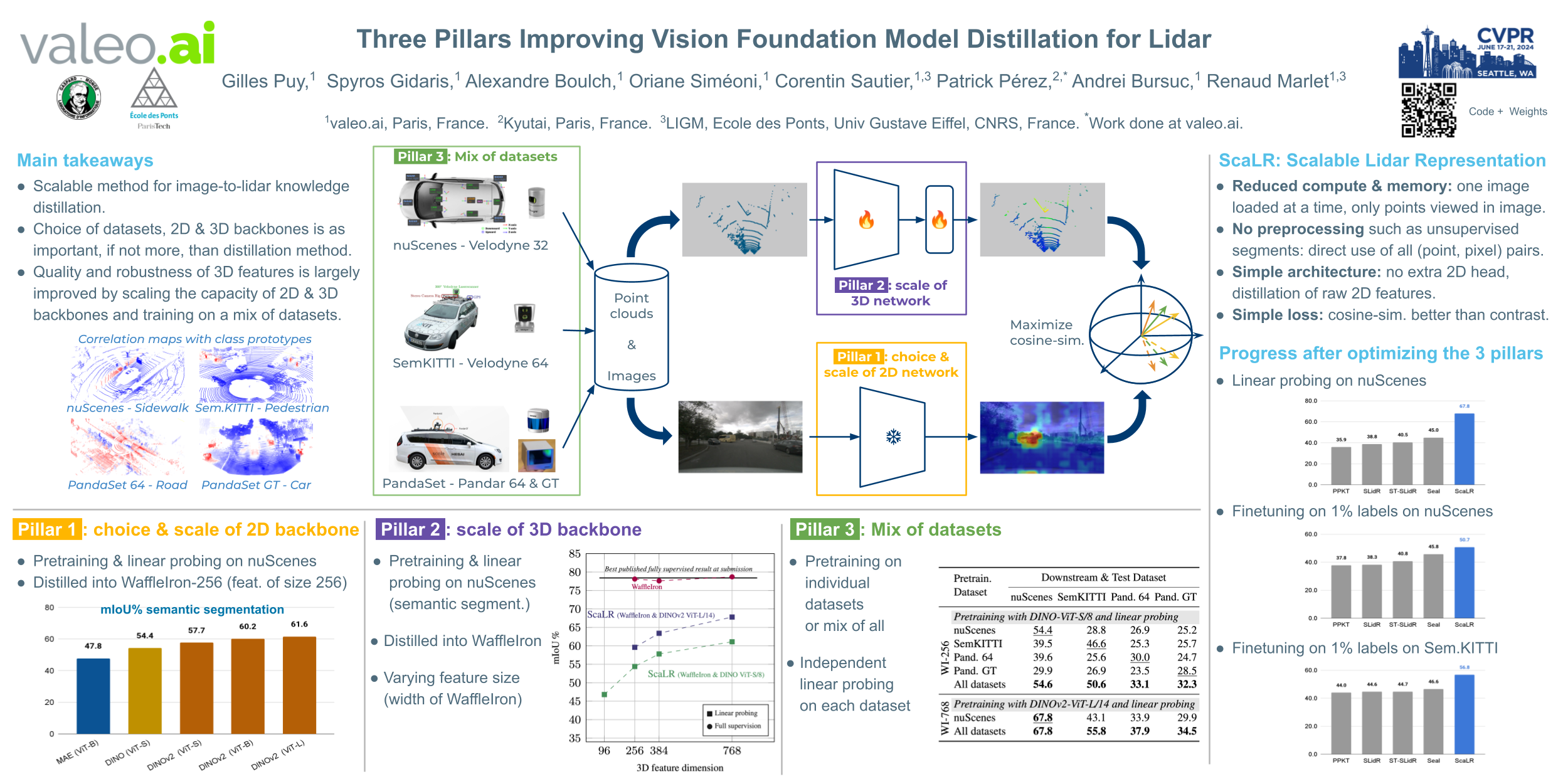
Self-supervised image backbones can be used to address complex 2D tasks (e.g., semantic segmentation, object discovery) very efficiently and with little or no downstream supervision. Ideally, 3D backbones for lidar should be able to inherit these properties after distillation of these powerful 2D features. The most recent methods for image-to-lidar distillation on autonomous driving data show promising results, obtained thanks to distillation methods that keep improving. Yet, we still notice a large performance gap when measuring the quality of distilled and fully supervised features by linear probing. In this work, instead of focusing only on the distillation method, we study the effect of three pillars for distillation: the 3D backbone, the pretrained 2D backbones, and the pretraining dataset. In particular, thanks to our scalable distillation method named ScaLR, we show that scaling the 2D and 3D backbones and pretraining on diverse datasets leads to a substantial improvement of the feature quality. This allows us to significantly reduce the gap between the quality of distilled and fully-supervised 3D features, and to improve the robustness of the pretrained backbones to domain gaps and perturbations.