A Closer Look at the Few-Shot Adaptation of Large Vision-Language Models
{kind=link}
Abstract
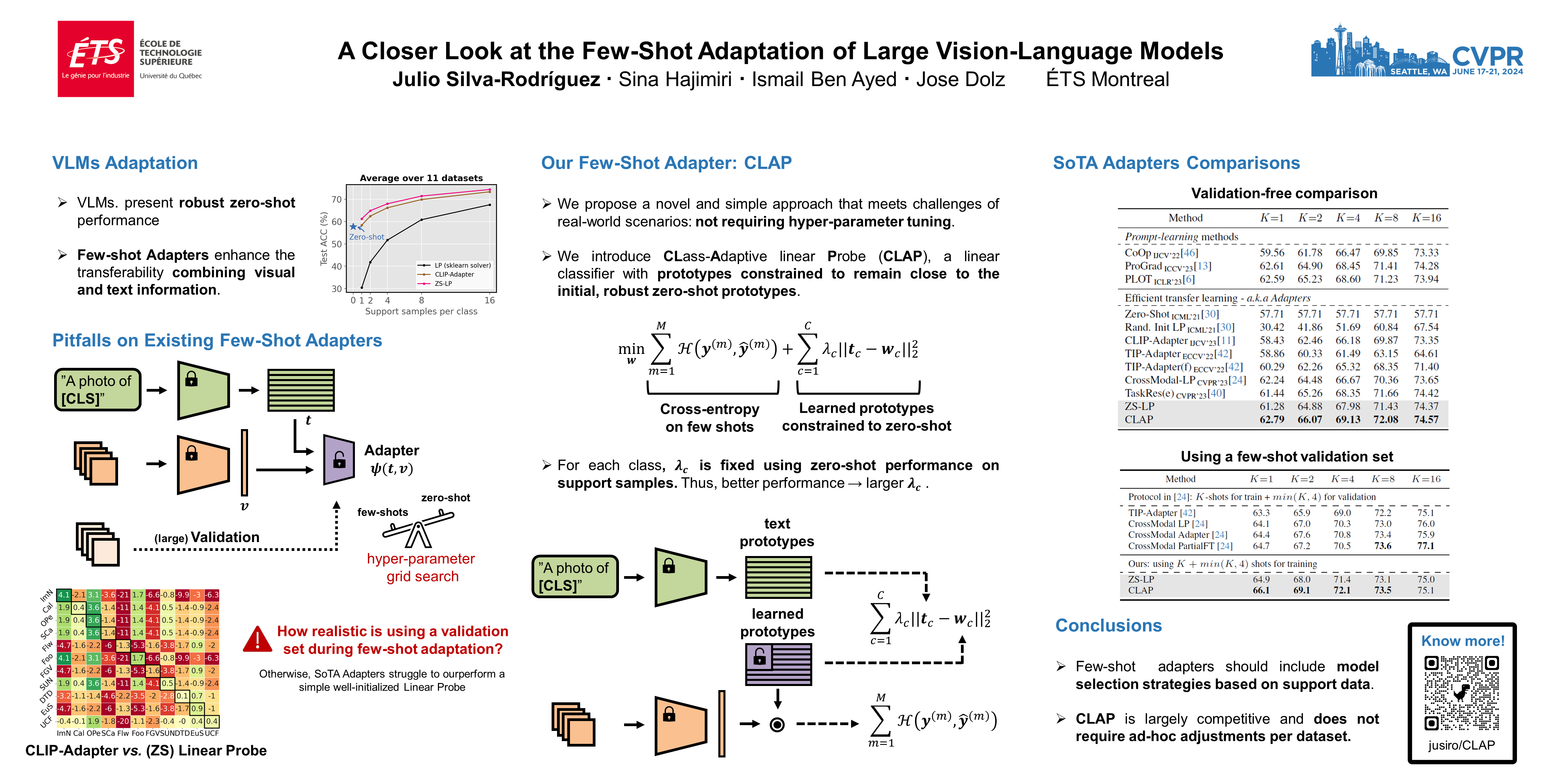
Efficient transfer learning (ETL) is receiving increasing attention to adapt large pre-trained language-vision models on downstream tasks with a few labeled samples. While significant progress has been made, we reveal that state-of-the-art ETL approaches exhibit strong performance only in narrowly-defined experimental setups, and with a careful adjustment of hyperparameters based on a large corpus of labeled samples. In particular, we make two interesting, and surprising empirical observations. First, to outperform a simple Linear Probing baseline, these methods require to optimize their hyper-parameters on each target task. And second, they typically underperform --sometimes dramatically-- standard zero-shot predictions in the presence of distributional drifts. Motivated by the unrealistic assumptions made in the existing literature, i.e., access to a large validation set and case-specific grid-search for optimal hyperparameters, we propose a novel approach that meets the requirements of real-world scenarios. More concretely, we introduce a CLass-Adaptive linear Probe (CLAP) objective, whose balancing term is optimized via an adaptation of the general Augmented Lagrangian method tailored to this context. We comprehensively evaluate CLAP on a broad span of datasets and scenarios, demonstrating that it consistently outperforms SoTA approaches, while yet being a much more efficient alternative.