GreedyViG: Dynamic Axial Graph Construction for Efficient Vision GNNs
Mustafa Munir ⋅ William Avery ⋅ Md Mostafijur Rahman ⋅ Radu Marculescu
2024 Poster
{kind=link}
Abstract
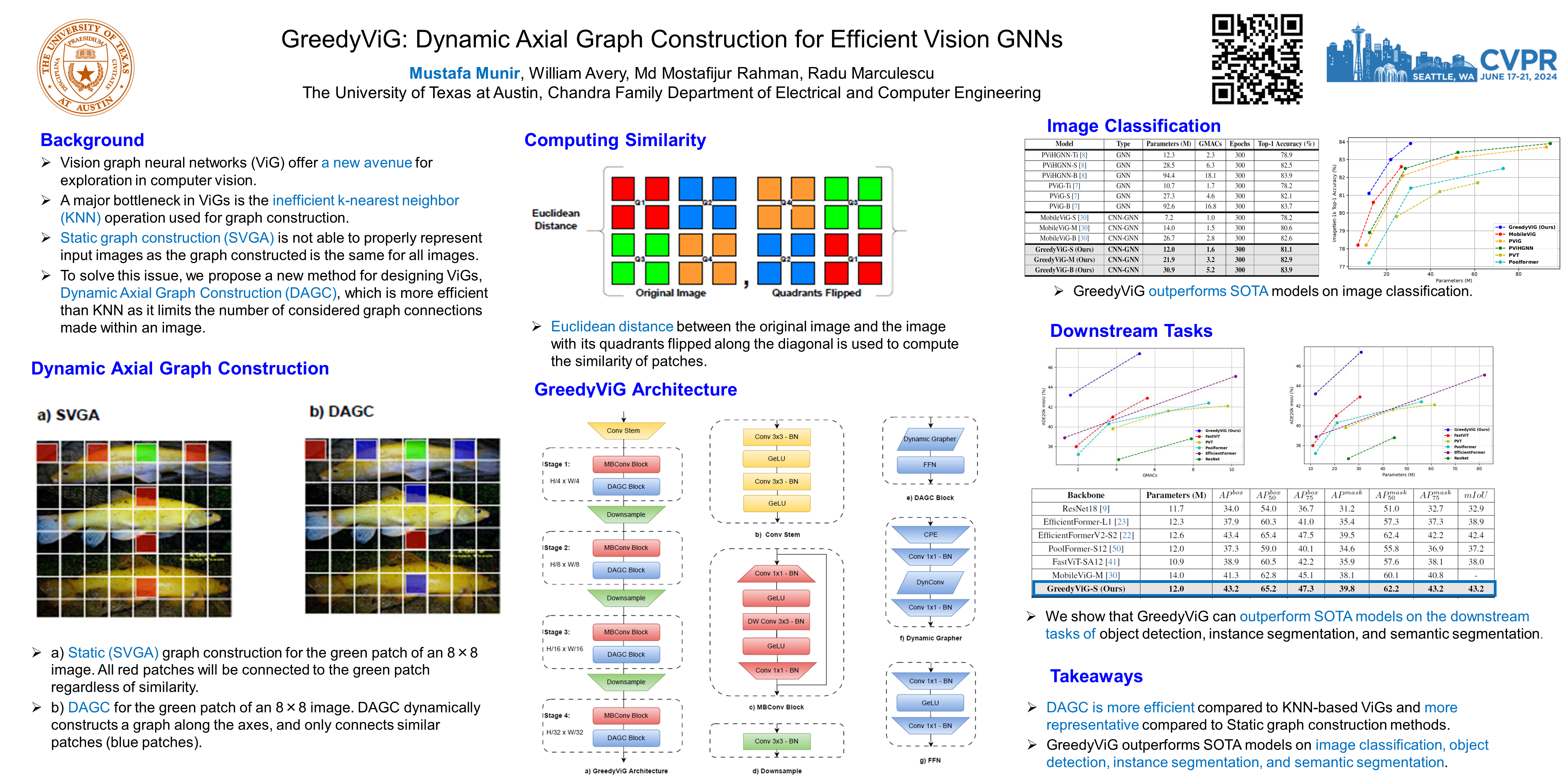
Vision graph neural networks (ViG) offer a new avenue for exploration in computer vision. A major bottleneck in ViGs is the inefficient k-nearest neighbor (KNN) operation used for graph construction. To solve this issue, we propose a new method for designing ViGs, Dynamic Axial Graph Construction (DAGC), which is more efficient than KNN as it limits the number of considered graph connections made within an image. Additionally, we propose a novel CNN-GNN architecture, GreedyViG, which uses DAGC. Extensive experiments show that GreedyViG beats existing ViG, CNN, and ViT architectures in terms of accuracy, GMACs, and parameters on image classification, object detection, instance segmentation, and semantic segmentation tasks. Our smallest model, GreedyViG-S, achieves 81.1\% top-1 accuracy on ImageNet-1K, 2.9\% higher than Vision GNN and 2.2\% higher than Vision HyperGraph Neural Network (ViHGNN), with less GMACs and a similar number of parameters. Our largest model, GreedyViG-B obtains 83.9\% top-1 accuracy, 0.2\% higher than Vision GNN, with a 66.6\% decrease in parameters and a 69\% decrease in GMACs. GreedyViG-B also obtains the same accuracy as ViHGNN with a 67.3\% decrease in parameters and a 71.3\% decrease in GMACs. Our work shows that hybrid CNN-GNN architectures not only provide a new avenue for designing efficient models, but that they can also exceed the performance of current state-of-the-art models$^1$.
Chat is not available.
Successful Page Load