Diffusion Time-step Curriculum for One Image to 3D Generation
{kind=link}
Abstract
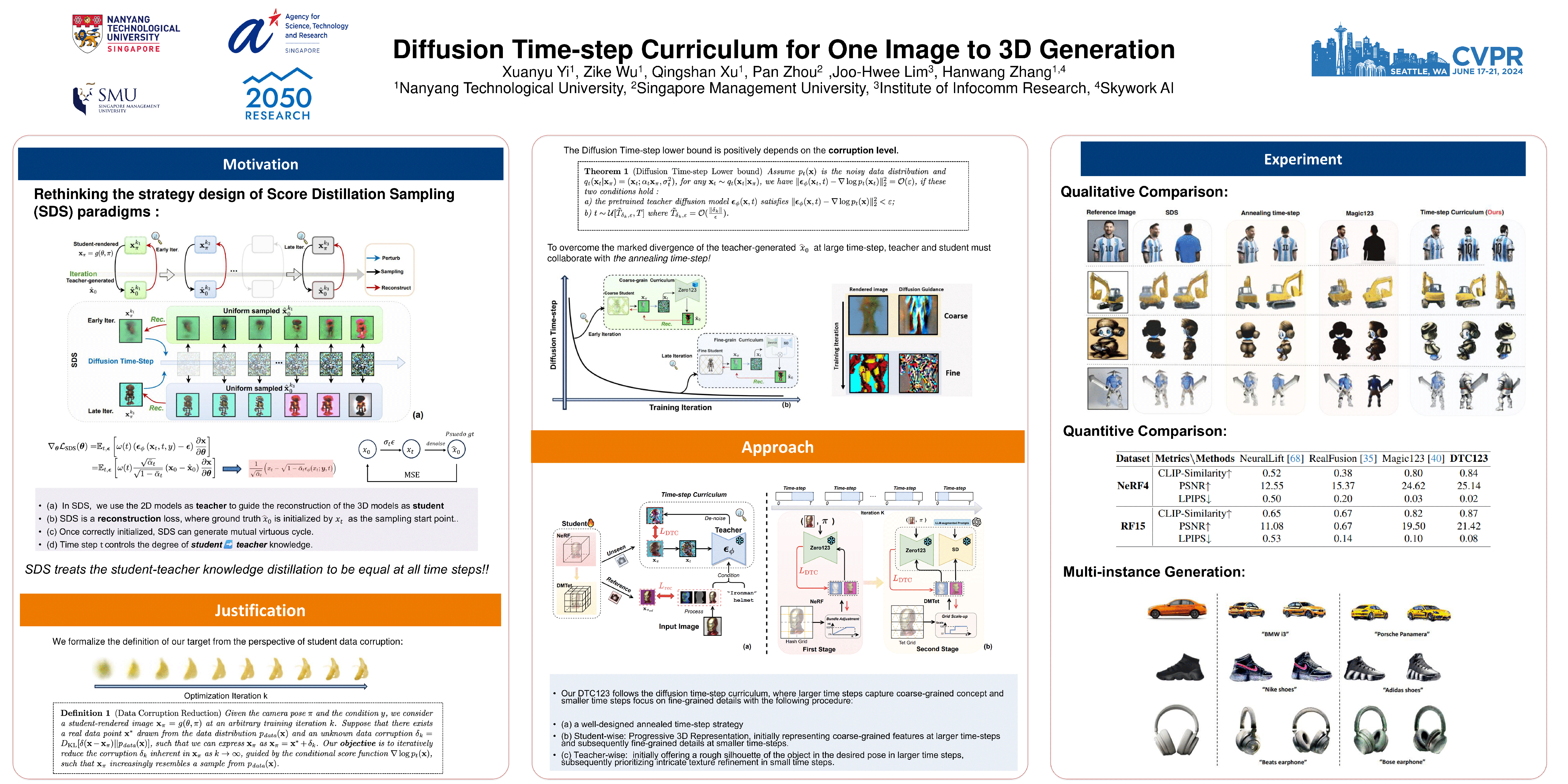
Score distillation sampling (SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a single mage. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite its remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets.