OMG-Seg: Is One Model Good Enough For All Segmentation?
{kind=link}
Abstract
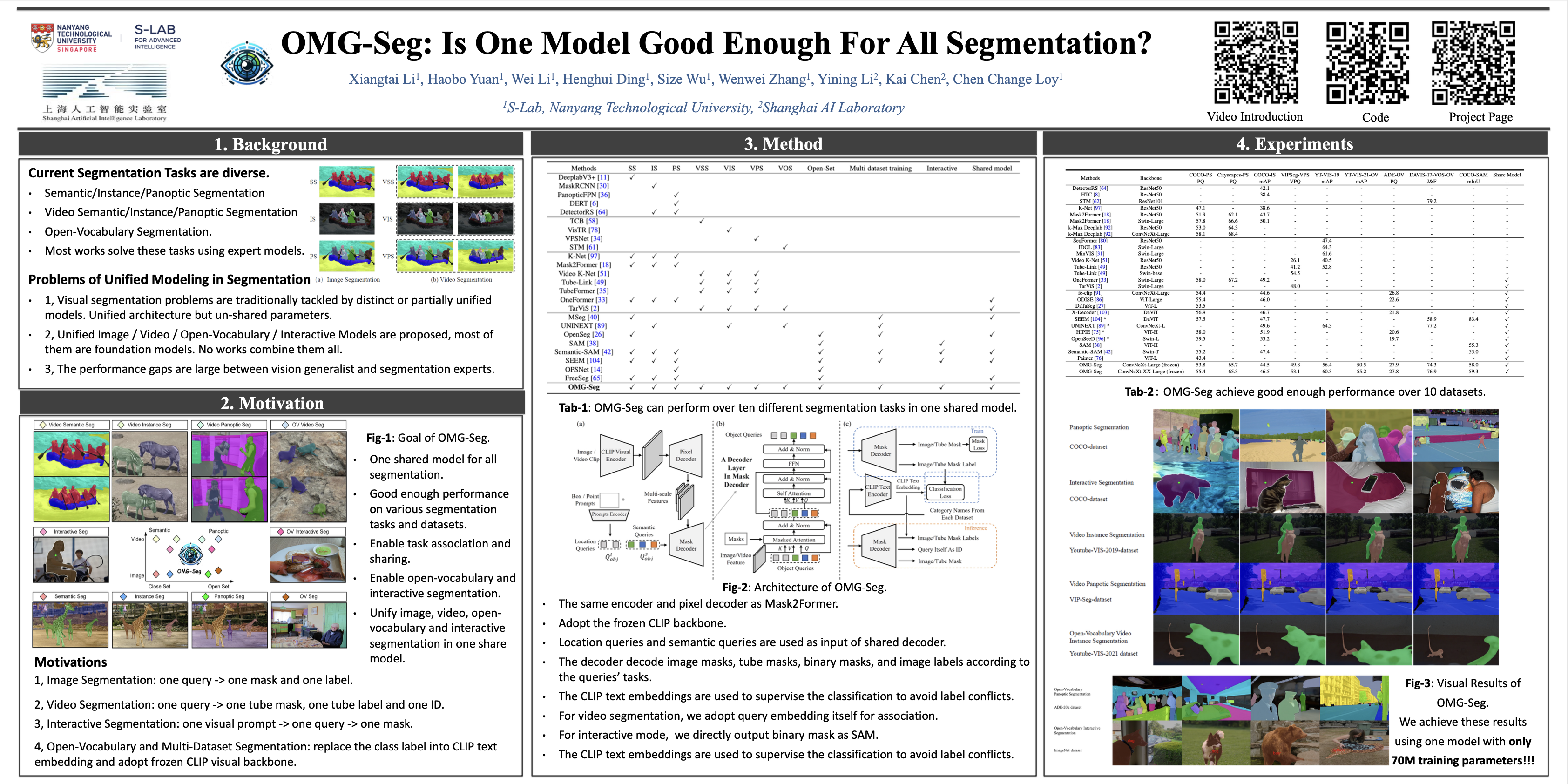
In this work, we address various segmentation tasks, each traditionally tackled by distinct or partially unified models. We propose OMG-Seg, One Model that is Good enough to efficiently and effectively handle all the segmentation tasks, including image semantic, instance, and panoptic segmentation, as well as their video counterparts, open vocabulary settings, prompt-driven, interactive segmentation like SAM, and video object segmentation. To our knowledge, this is the first model to fill all these tasks in one model and achieve good enough performance. We show that OMG-Seg, a transformer-based encoder-decoder architecture with task-specific queries and outputs, can support over ten distinct segmentation tasks and yet significantly reduce computational and parameter overhead across various tasks and datasets. We rigorously evaluate the inter-task influences and correlations during co-training. Code and models are available at \url{https://github.com/lxtGH/OMG-Seg}.